can be quite hard to find a specific dataset to use for a variety of machine learning problems or to even experiment on. The list below does not only contain great datasets for experimentation but also contains a description, usage examples and in some cases the algorithm code to solve the machine learning problem associated with that dataset.
1- Kaggle Datasets
This
is one of my favourite dataset locations. Each dataset is a small
community where you can have a discussion about data, find some public
code or create your own projects in Kernels. They contain a numerous
amount of real-life datasets of all shapes and sizes and in many
different formats. You can also see “Kernels” associated with each
dataset where many different data scientists have provided notebooks to
analyze the dataset. Sometimes you can find notebooks with algorithms
that solve the prediction problem in this specific dataset.
2- Amazon Datasets
This
source contains many datasets in different fields such as: (Public
Transport, Ecological Resources, Satellite Images, etc.). It also has a
search box to help you find the dataset you are looking for and it also
has dataset description and Usage examples for all datasets which are very informative and easy to use!
The datasets are stored in Amazon Web Services (AWS) resources such as Amazon S3 — A
highly scalable object storage service in the Cloud. If you are using
AWS for machine learning experimentation and development, that will be
handy as the transfer of the datasets will be very quick because it is
local to the AWS network.
3- UCI Machine Learning Repository:
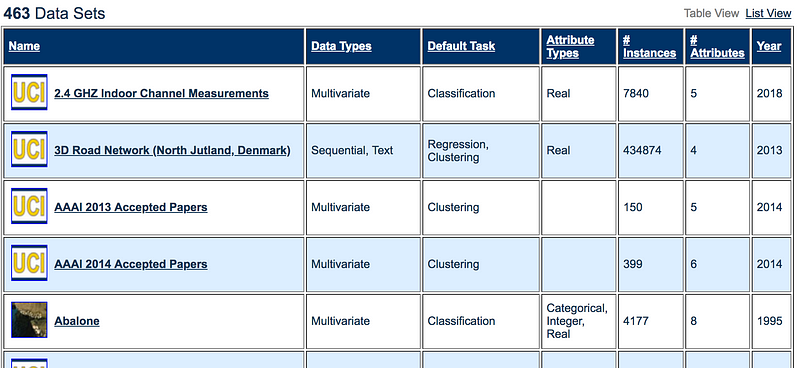
Another great repository of 100s of datasets
from the University of California, School of Information and Computer
Science. It classifies the datasets by the type of machine learning
problem. You can find datasets for univariate and multivariate
time-series datasets, classification, regression or recommendation
systems. Some of the datasets at UCI are already cleaned and ready to be
used.
4- Google’s Datasets Search Engine:
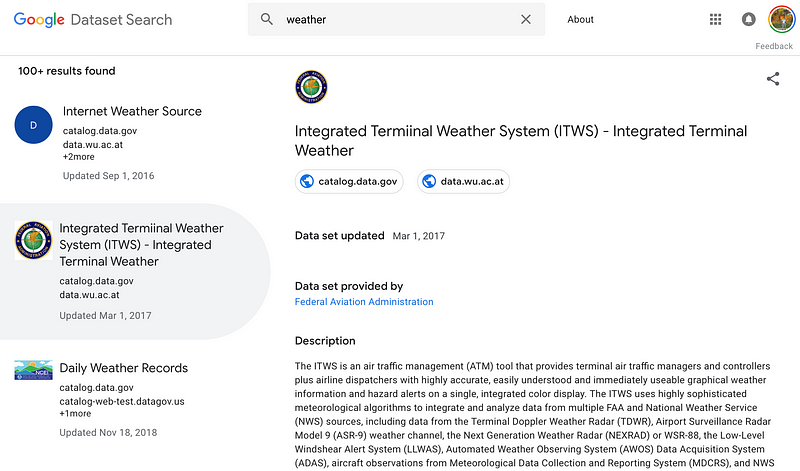
In
late 2018, Google did what they do best and launched another great
service. It is a toolbox that can search for datasets by name. Their aim
is to unify tens of thousands of different repositories for datasets
and make that data discoverable. Well done, Google.
5- Microsoft Datasets:
In July 2018, Microsoft along with the external research community announced the launch of “Microsoft Research Open Data”
It
contains a data repository in the cloud dedicated to facilitating
collaboration across the global research community. It offers a bunch of
curated datasets that were used in published research studies.
6- Awesome Public Datasets Collection:
This
is a great source of datasets organized by topics, such as Biology,
Economics, Education, etc. Most of the datasets listed there are free,
but you should always check the licensing requirements before using any
dataset.
7- Government Datasets:
It’s
also easy to find government-related datasets. Many countries have
shared a variety of datasets to the public as an exercise of
transparency. Here are some examples:
- EU Open Data Portal: European Government Datasets.
- US Gov Data (Not to get political, but this website is temporarily unavailable due to Trump’s Government Shutdown or “lack of funding” as mentioned on the main page).
- New Zealand’s Government Dataset.
- Indian Government Dataset.
- https://www.opendatani.gov.uk/ (Northern Ireland Public Dataset)
8- Computer Vision Datasets:
If
you are working on image processing, computer vision or deep learning
then this should be your source of data for experiments.
Visual
Data contains a handful number of great datasets that can be used to
build computer vision (CV) models. You can look for a certain dataset by
a certain CV subject such as Semantic Segmentation, Image captioning,
Image Generation or even by the solution such as (Self-driving cars
dataset).
In
conclusion, from what I observe, it seems like there is a global
direction towards making more and more data available and easily
reachable to the research and machine learning community. Those new
datasets’ communities will continue to grow and make the data easily
accessible so that the crowdsource and the computer science community
can continue to innovate fast and bring more creative solutions to life.
No comments:
Post a Comment