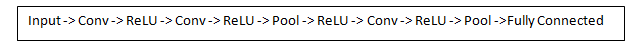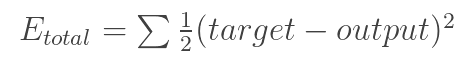A Beginner's Guide To Understanding Convolutional Neural Networks
Introduction
Convolutional neural networks. Sounds like a weird
combination of biology and math with a little CS sprinkled in, but these
networks have been some of the most influential innovations in the
field of computer vision. 2012 was the first year that neural nets grew
to prominence as Alex Krizhevsky used them to win that year’s ImageNet
competition (basically, the annual Olympics of computer vision),
dropping the classification error record from 26% to 15%, an astounding
improvement at the time.Ever since then, a host of companies have been
using deep learning at the core of their services. Facebook uses neural
nets for their automatic tagging algorithms, Google for their photo
search, Amazon for their product recommendations, Pinterest for their
home feed personalization, and Instagram for their search
infrastructure.
However, the classic, and arguably most popular, use case of these
networks is for image processing. Within image processing, let’s take a
look at how to use these CNNs for image classification.
The Problem Space
Image classification is the task of taking an input
image and outputting a class (a cat, dog, etc) or a probability of
classes that best describes the image. For humans, this task of
recognition is one of the first skills we learn from the moment we are
born and is one that comes naturally and effortlessly as adults. Without
even thinking twice, we’re able to quickly and seamlessly identify the
environment we are in as well as the objects that surround us. When we
see an image or just when we look at the world around us, most of the
time we are able to immediately characterize the scene and give each
object a label, all without even consciously noticing. These skills of
being able to quickly recognize patterns, generalize from prior
knowledge, and adapt to different image environments are ones that we do
not share with our fellow machines.
Inputs and Outputs
When a computer sees an image (takes an image as
input), it will see an array of pixel values. Depending on the
resolution and size of the image, it will see a 32 x 32 x 3 array of
numbers (The 3 refers to RGB values). Each of these numbers is given a
value from 0 to 255 which describes the pixel intensity at that point.
These numbers, while meaningless to us when we perform image
classification, are the only inputs available to the computer. The idea
is that you give the computer this array of numbers and it will output
numbers that describe the probability of the image being a certain class
(.80 for cat, .15 for dog, .05 for bird, etc).
What We Want the Computer to Do
Now that we know the problem as well as the inputs
and outputs, let’s think about how to approach this. What we want the
computer to do is to be able to differentiate between all the images
it’s given and figure out the unique features that make a dog a dog or
that make a cat a cat. This is the process that goes on in our minds
subconsciously as well. When we look at a picture of a dog, we can
classify it as such if the picture has identifiable features such as
paws or 4 legs. In a similar way, the computer is able perform image
classification by looking for low level features such as edges and
curves, and then building up to more abstract concepts through a series
of convolutional layers. This is a general overview of what a CNN does.
Let’s get into the specifics.
Biological Connection
But first, a little background. When you first heard
of the term convolutional neural networks, you may have thought of
something related to neuroscience or biology, and you would be right.
Sort of. CNNs do take a biological inspiration from the visual cortex.
The visual cortex has small regions of cells that are sensitive to
specific regions of the visual field. This idea was expanded upon by a
fascinating experiment by Hubel and Wiesel in 1962 (Video)
where they showed that some individual neuronal cells in the brain
responded (or fired) only in the presence of edges of a certain
orientation. For example, some neurons fired when exposed to vertical
edges and some when shown horizontal or diagonal edges. Hubel and Wiesel
found out that all of these neurons were organized in a columnar
architecture and that together, they were able to produce visual
perception. This idea of specialized components inside of a system
having specific tasks (the neuronal cells in the visual cortex looking
for specific characteristics) is one that machines use as well, and is
the basis behind CNNs.
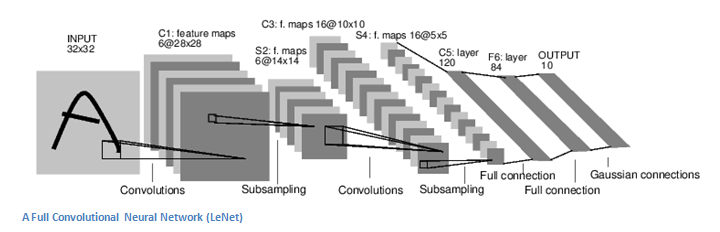
Structure
Back to the specifics. A more detailed overview of
what CNNs do would be that you take the image, pass it through a series
of convolutional, nonlinear, pooling (downsampling), and fully connected
layers, and get an output. As we said earlier, the output can be a
single class or a probability of classes that best describes the image.
Now, the hard part is understanding what each of these layers do. So
let’s get into the most important one.
First Layer – Math Part
The first layer in a CNN is always a Convolutional Layer.
First thing to make sure you remember is what the input to this conv
(I’ll be using that abbreviation a lot) layer is. Like we mentioned
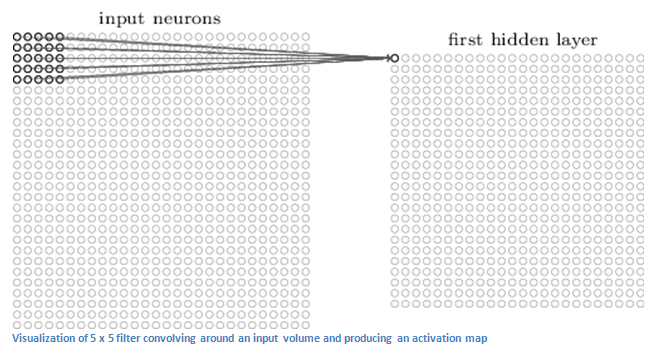
before, the input is a 32 x 32 x 3 array of pixel values. Now, the best
way to explain a conv layer is to imagine a flashlight that is shining
over the top left of the image. Let’s say that the light this flashlight
shines covers a 5 x 5 area. And now, let’s imagine this flashlight
sliding across all the areas of the input image. In machine learning
terms, this flashlight is called a filter(or sometimes referred to as a neuron or a kernel) and the region that it is shining over is called the receptive field. Now this filter is also an array of numbers (the numbers are called weights or parameters).
A very important note is that the depth of this filter has to be the
same as the depth of the input (this makes sure that the math works
out), so the dimensions of this filter is 5 x 5 x 3. Now, let’s take the
first position the filter is in for example. It would be the top left
corner. As the filter is sliding, or convolving, around the input image, it is multiplying the values in the filter with the original pixel values of the image (aka computing dot products).
These multiplications are all summed up (mathematically speaking, this
would be 75 multiplications in total). So now you have a single number.
Remember, this number is just representative of when the filter is at
the top left of the image. Now, we repeat this process for every
location on the input volume. (Next step would be moving the filter to
the right by 1 unit, then right again by 1, and so on). Every unique
location on the input volume produces a number. After sliding the filter
over all the locations, you will find out that what you’re left with is
a 28 x 28 x 1 array of numbers, which we call an activation map or feature map.
The reason you get a 28 x 28 array is that there are 784 different
locations that a 5 x 5 filter can fit on a 32 x 32 input image. These
784 numbers are mapped to a 28 x 28 array.
Let’s say now we use two 5 x 5 x 3 filters instead of one. Then our
output volume would be 28 x 28 x 2. By using more filters, we are able
to preserve the spatial dimensions better. Mathematically, this is
what’s going on in a convolutional layer.
First Layer – High Level Perspective
However, let’s talk about what this convolution is
actually doing from a high level. Each of these filters can be thought
of as feature identifiers. When I say features, I’m
talking about things like straight edges, simple colors, and curves.
Think about the simplest characteristics that all images have in common
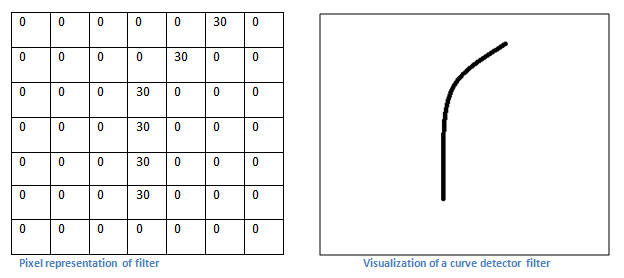
with each other. Let’s say our first filter is 7 x 7 x 3 and is going to
be a curve detector. (In this section, let’s ignore the fact that the
filter is 3 units deep and only consider the top depth slice of the
filter and the image, for simplicity.)As a curve detector, the filter
will have a pixel structure in which there will be higher numerical
values along the area that is a shape of a curve (Remember, these
filters that we’re talking about as just numbers!).
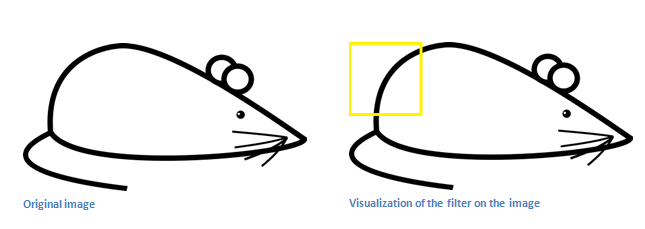
Now, let’s go back to visualizing this
mathematically. When we have this filter at the top left corner of the
input volume, it is computing dot products between the filter and pixel
values at that region. Now let’s take an example of an image that we
want to classify, and let’s put our filter at the top left corner.
Remember, what we have to do is multiply the values in the filter with the original pixel values of the image.
Basically, in the input image, if there is a shape that generally
resembles the curve that this filter is representing, then all of the
dot products summed together will result in a large value! Now let’s see
what happens when we move our filter.
The value is much lower! This is because
there wasn’t anything in the image section that responded to the curve
detector filter. Remember, the output of this conv layer is an
activation map. So, in the simple case of a one filter convolution (and
if that filter is a curve detector), the activation map will show the
areas in which there at mostly likely to be curves in the picture. In
this example, the top left value of our 28 x 28 x 1 activation map will
be 6600. This high value means that it is likely that there is some sort
of curve in the input volume that caused the filter to activate. The
top right value in our activation map will be 0 because there wasn’t
anything in the input volume that caused the filter to activate (or more
simply said, there wasn’t a curve in that region of the original
image). Remember, this is just for one filter. This is just a filter
that is going to detect lines that curve outward and to the right. We
can have other filters for lines that curve to the left or for straight
edges. The more filters, the greater the depth of the activation map,
and the more information we have about the input volume.
Disclaimer: The filter I
described in this section was simplistic for the main purpose of
describing the math that goes on during a convolution. In the picture
below, you’ll see some examples of actual visualizations of the filters
of the first conv layer of a trained network. Nonetheless, the main
argument remains the same. The filters on the first layer convolve
around the input image and “activate” (or compute high values) when the
specific feature it is looking for is in the input volume.
Going Deeper Through the Network
Now in a traditional
convolutional neural network architecture, there are other layers that
are interspersed between these conv layers. I’d strongly encourage those
interested to read up on them and understand their function and
effects, but in a general sense, they provide nonlinearities and
preservation of dimension that help to improve the robustness of the
network and control overfitting. A classic CNN architecture would look
like this.
The last layer, however, is an important
one and one that we will go into later on. Let’s just take a step back
and review what we’ve learned so far. We talked about what the filters
in the first conv layer are designed to detect. They detect low level
features such as edges and curves. As one would imagine, in order to
predict whether an image is a type of object, we need the network to be
able to recognize higher level features such as hands or paws or ears.
So let’s think about what the output of the network is after the first
conv layer. It would be a 28 x 28 x 3 volume (assuming we use three 5 x 5
x 3 filters). When we go through another conv layer, the output of the
first conv layer becomes the input of the 2nd conv layer.
Now, this is a little bit harder to visualize. When we were talking
about the first layer, the input was just the original image. However,
when we’re talking about the 2nd conv layer, the input is the
activation map(s) that result from the first layer. So each layer of
the input is basically describing the locations in the original image
for where certain low level features appear. Now when you apply a set of
filters on top of that (pass it through the 2nd conv layer),
the output will be activations that represent higher level features.
Types of these features could be semicircles (combination of a curve and
straight edge) or squares (combination of several straight edges). As
you go through the network and go through more conv layers, you get
activation maps that represent more and more complex features. By the
end of the network, you may have some filters that activate when there
is handwriting in the image, filters that activate when they see pink
objects, etc. If you want more information about visualizing filters in
ConvNets, Matt Zeiler and Rob Fergus had an excellent research paper discussing the topic. Jason Yosinski also has a video
on YouTube that provides a great visual representation. Another
interesting thing to note is that as you go deeper into the network, the
filters begin to have a larger and larger receptive field, which means
that they are able to consider information from a larger area of the
original input volume (another way of putting it is that they are more
responsive to a larger region of pixel space).
Fully Connected Layer
Now that we can detect these high level features, the icing on the cake is attaching a fully connected layer
to the end of the network. This layer basically takes an input volume
(whatever the output is of the conv or ReLU or pool layer preceding it)
and outputs an N dimensional vector where N is the number of classes
that the program has to choose from. For example, if you wanted a digit
classification program, N would be 10 since there are 10 digits. Each
number in this N dimensional vector represents the probability of a
certain class. For example, if the resulting vector for a digit
classification program is [0 .1 .1 .75 0 0 0 0 0 .05], then this
represents a 10% probability that the image is a 1, a 10% probability
that the image is a 2, a 75% probability that the image is a 3, and a 5%
probability that the image is a 9 (Side note: There are other ways that
you can represent the output, but I am just showing the softmax
approach). The way this fully connected layer works is that it looks at
the output of the previous layer (which as we remember should represent
the activation maps of high level features) and determines which
features most correlate to a particular class. For example, if the
program is predicting that some image is a dog, it will have high values
in the activation maps that represent high level features like a paw or
4 legs, etc. Similarly, if the program is predicting that some image is
a bird, it will have high values in the activation maps that represent
high level features like wings or a beak, etc. Basically, a FC layer
looks at what high level features most strongly correlate to a
particular class and has particular weights so that when you compute the
dot product between the weights and the previous layer, you get the
correct probabilities for the different classes.
Training (AKA:What Makes this Stuff Work)
Now, this is the one aspect
of neural networks that I purposely haven’t mentioned yet and it is
probably the most important part. There may be a lot of questions you
had while reading. How do the filters in the first conv layer know to
look for edges and curves? How does the fully connected layer know what
activation maps to look at? How do the filters in each layer know what
values to have? The way the computer is able to adjust its filter values
(or weights) is through a training process called backpropagation.
Before we get into backpropagation, we must
first take a step back and talk about what a neural network needs in
order to work. At the moment we all were born, our minds were fresh. We
didn’t know what a cat or dog or bird was. In a similar sort of way,
before the CNN starts, the weights or filter values are randomized. The
filters don’t know to look for edges and curves. The filters in the
higher layers don’t know to look for paws and beaks. As we grew older
however, our parents and teachers showed us different pictures and
images and gave us a corresponding label. This idea of being given an
image and a label is the training process that CNNs go through. Before
getting too into it, let’s just say that we have a training set that has
thousands of images of dogs, cats, and birds and each of the images has
a label of what animal that picture is. Back to backprop.
So backpropagation can be separated into 4
distinct sections, the forward pass, the loss function, the backward
pass, and the weight update. During the forward pass,
you take a training image which as we remember is a 32 x 32 x 3 array of
numbers and pass it through the whole network. On our first training
example, since all of the weights or filter values were randomly
initialized, the output will probably be something like [.1 .1 .1 .1 .1
.1 .1 .1 .1 .1], basically an output that doesn’t give preference to any
number in particular. The network, with its current weights, isn’t able
to look for those low level features or thus isn’t able to make any
reasonable conclusion about what the classification might be. This goes
to the loss function part of backpropagation. Remember
that what we are using right now is training data. This data has both an
image and a label. Let’s say for example that the first training image
inputted was a 3. The label for the image would be [0 0 0 1 0 0 0 0 0
0]. A loss function can be defined in many different ways but a common
one is MSE (mean squared error), which is ½ times (actual - predicted)
squared.
Let’s say the variable L is equal to that
value. As you can imagine, the loss will be extremely high for the first
couple of training images. Now, let’s just think about this
intuitively. We want to get to a point where the predicted label (output
of the ConvNet) is the same as the training label (This means that our
network got its prediction right).In order to get there, we want to
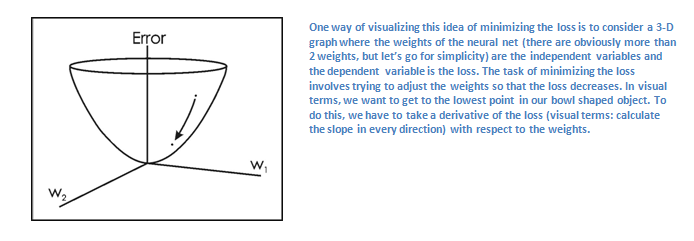
minimize the amount of loss we have. Visualizing this as just an
optimization problem in calculus, we want to find out which inputs
(weights in our case) most directly contributed to the loss (or error)
of the network.
This is the mathematical equivalent of a dL/dW where W are the weights at a particular layer. Now, what we want to do is perform a backward pass
through the network, which is determining which weights contributed
most to the loss and finding ways to adjust them so that the loss
decreases. Once we compute this derivative, we then go to the last step
which is the weight update. This is where we take all the weights of the filters and update them so that they change in the direction of the gradient.
The learning rate is a
parameter that is chosen by the programmer. A high learning rate means
that bigger steps are taken in the weight updates and thus, it may take
less time for the model to converge on an optimal set of weights.
However, a learning rate that is too high could result in jumps that are
too large and not precise enough to reach the optimal point.
The process of forward pass, loss function, backward pass, and parameter update is generally called one epoch.
The program will repeat this process for a fixed number of epochs for
each training image. Once you finish the parameter update on the last
training example, hopefully the network should be trained well enough so
that the weights of the layers are tuned correctly.
Testing
Finally, to see whether or
not our CNN works, we have a different set of images and labels (can’t
double dip between training and test!) and pass the images through the
CNN. We compare the outputs to the ground truth and see if our network
works!
How Companies Use CNNs
Data, data, data. The
companies that have lots of this magic 4 letter word are the ones that
have an inherent advantage over the rest of the competition. The more
training data that you can give to a network, the more training
iterations you can make, the more weight updates you can make, and the
better tuned to the network is when it goes to production. Facebook (and
Instagram) can use all the photos of the billion users it currently
has, Pinterest can use information of the 50 billion pins that are on
its site, Google can use search data, and Amazon can use data from the
millions of products that are bought every day. And now you know the
magic behind how they use it.
Disclaimer
While this post should be a
good start to understanding CNNs, it is by no means a comprehensive
overview. Things not discussed in this post include the nonlinear and
pooling layers as well as hyperparameters of the network such as filter
sizes, stride, and padding. Topics like network architecture, batch
normalization, vanishing gradients, dropout, initialization techniques,
non-convex optimization,biases, choices of loss functions, data
augmentation,regularization methods, computational considerations,
modifications of backpropagation, and more were also not discussed (yet ).
Last week, Peter and I gave a tutorial at SciPy 2016. In keeping with our recent thinking
about reproducibility and organization, the idea was
to look at how some of the hard-won lessons and best practices from modern software engineering can be applied
to data science work.
We ran a little short on time near the end, partly because a few people ran into pretty wild open bugs and
configuration issues during the virtual environment lab, and partly because we tried to fit a bunch of
varied subjects into one tutorial. But overall, I think it ended up being a pretty good session.
The repo with slides, notebooks, and other materials is here.
Here's the talk:
There
seems to be very little overlap currently between the worlds of infosec
and machine learning. If a data scientist attended Black Hat and a
network security expert went to NIPS, they would be equally at a loss.
This
is unfortunate because infosec can definitely benefit from a
probabilistic approach but a significant amount of domain expertise is
required in order to apply ML methods.
Machine learning
practitioners face a few challenges for doing work in this domain
including understanding the datasets, how to do feature engineering (in a
generalizable way) and creation of labels.
Available DatasetS
A variety of datasets can be collected as a precursor to creating a training set for a machine learning model:
Log
files from systems, firewalls, proxies, routers, switches that capture
in semi-structured formats network activity and user behavior
Application level logging and diagnostics that record user/system access information and application usage
Monitoring tools, IDS systems and SIEMs
Network Packet Capture (PCAP) is a rather compute/storage intensive process of recording the raw ethernet frames
Some
of these sources (like log formats) are readily available and fairly
standardized while others will require extensive tooling and software
modifications (e.g. application logging), and yet others will require a
significant hardware footprint and a monitoring network that could rival
the size of the real network.
Feature Engineering
Bearing
in mind that the whole point of machine learning is generalization
beyond the training set, thoughtful feature engineering is required to
go from the identity information of IP addresses, hostnames and URLs to
something that can turn into a useful representation within the machine
learning model.
For example the following might be a useful feature space created from proxy logs (Franc)
length
digit ratio
lower case ratio
upper case ratio
vowel changes ratio
has repetition of '&' and '='
start with number
number of non-base64 characters
has a special character
max length of consonant stream
max length of vowel stream
max length of lower case stream
max length of upper case stream
max length of digit stream
ratio of a character with max occurrence
(session) duration
HTTP request status
is URL encrypted
is protocol HTTPS
number of bytes up
number of bytes down
is URL in ASCII
client port number
server port number
user agent length
MIME-Type length
number of '/' in path
number of '/' in query
number of '/' in referrer
is the second-level domain raw IP
getting labels
Once
the input feature space has been established, getting the label is the
next challenge. For each observation of the training set, we need to
determine if it is a malicious or a benign pattern.
Having a
network security expert create labels (on potentially millions of
observations) will be expensive and time consuming. Instead we might
rely on a semi-supervised approach by leveraging publicly available
threat intelligence feeds. MLSec provides a set of tools and resources for gathering and processing various threat intelligence feeds.*
Thus
labels are created by doing a join between public blacklists and the
collected dataset. Matching can be done on fields like IP addresses,
domains, agents, etc. Keep in mind that these identity elements are only
used to produce the label and will not be part of the model input
(Franc).
Modeling considerations
Finally once we have the
input feature space and the labels, we are ready to train a model. We
can anticipate certain characteristics of input space such as class
imbalance, non-linearity and noisiness. A modern ensemble method like
random forest or gradient boosted trees should overcome these issues
with proper parameter tuning (Seni).
Bigger issue is that this is
an adversarial use case and model decay will be a significant factor.
Since there is an active adversary trying to avoid detection, attack
patterns will constantly evolve which will cause data drift for the
model.
Some possible solutions to the adversarial issue could be
the use of a nonparametric method, using online/active learning (i.e.
letting the model evolve on every new observation) or having rigorous
tests to determine when the model should be retrained.
LEARNING MORE
To address some of the issues unique to adversarial machine learning, Startup.ML is organizing a one-day special conference on
September 10th in San Francisco. Leading practitioners from Google,
Coinbase, Ripple, Stripe, Square, etc. will cover their approaches to
solving these problems in hands-on workshops and talks.
The conference will also include a hands-on, 90 minute tutorial on TensorFlow by Illia Polosukhin one of the most active contributors to Google's new deep learning library.
Pandas has got to be one of my most favourite libraries… Ever.
Pandas allows us to deal with data in a way that us humans can
understand it; with labelled columns and indexes. It allows us to
effortlessly import data from files such as csvs, allows us to quickly
apply complex transformations and filters to our data and much more.
It’s absolutely brilliant.
Along with Numpy and Matplotlib I feel
it helps create a really strong base for data exploration and analysis
in Python. Scipy (which will be covered in the next post), is of course a
major component and another absolutely fantastic library, but I feel
these three are the real pillars of scientific Python.
So without
any ado, let’s get on with the third post in this series on scientific
Python and take a look at Pandas. Don’t forget to check out the other
posts if you haven’t yet!
IMPORTING PANDAS
First thing to do its to import the star of the show, Pandas.
1
import pandas aspd# This is the standard
This
is the standard way to import Pandas. We don’t want to be writing
‘pandas’ all the time but it’s important to keep code concise and avoid
naming clashes so we compromise with ‘pd’. If you look at other people’s
code that uses Pandas you will see this import.
THE PANDAS DATA TYPES
Pandas is based around two data types, the series and the dataframe.
A series is a one-dimensional data type where each element is labelled. If you have read the post in this series on NumPy, you can think of it as a numpy array with labelled elements. Labels can be numeric or strings.
A
dataframe is a two-dimensional, tabular data structure. The Pandas
dataframe can store many different data types and each axis is labelled.
You can think of it as sort of like a dictionary of series.
GETTING DATA INTO PANDAS
Before
we can start wrangling, exploring and analysing, we first need data to
wrangle, explore and analyse. Thanks to Pandas this is very easy, more
so than NumPy.
Here I encourage you to find your own dataset, one
that interests you and play around with that. Some good resources to
find datasets are your country’s (or another’s) website. If you search
for example UK government data or US government data, it will be one of the first results. Kaggle is another great source.
I
will be using data on the UK’s rainfall that I found on the UK
government’s website which can easily be downloaded and towards the end,
some data that I got off a website about Japan’s rainfall.
Here
we get data from a csv file and store it in a dataframe. It’s as simple
as calling read_csv and putting the path to your csv file as an
argument. The header keyword argument tells Pandas if and where the
column names of your data are. If there are no column names you can set
it to None. Pandas is pretty clever so this can often be omitted.
GETTING YOUR DATA READY TO EXPLORE AND ANALYSE
Now
we have our data in Pandas, we probably want to take a quick look at it
and know some basic information about it to give us some direction
before we really probe into it.
To take a quick look at the first x rows of the data.
1
2
# Getting first x rows.
df.head(5)
All we do is use the head() function and pass it the number of rows we want to retrieve.
You’ll end up with table looking like this:
Another thing you might want to do is get the last x rows.
1
2
# Getting last x rows.
df.tail(5)
As
with head all we do is call tail and pass it the number of rows we want
to retrieve. Notice that it doesn’t start at the end of the dataframe
and goes backwards. It gives you the rows in the order they are in in
the dataframe.
You will end up with something that looks like this:
When
referring to columns in Pandas you often refer to their names. This
great and very easy to work with, but sometimes data has horribly long
column names, such as whole questions from questionnaires. Life is much
easier when you change them to make them shorter.
One
thing to note here is that I have purposely made all the column labels
with no spaces and no dashes. If we name our variables like this, it
saves us some typing as you will see later.
You will end up with the same data as before, but with different column names:
Another
important thing about your data that you will usually want to know is
how many entries you have. In Pandas one entry equates to one row, so we
can take the len of the dataset, which returns the amount of rows there
are.
1
2
# Finding out how many rows dataset has.
len(df)
This will give you an integer telling you the number of rows, in my dataset I have 33.
One more thing that you might need to know is some basic statistics on your data, Pandas makes this delightfully simple.
1
2
3
# Finding out basic statistical information on your dataset.
pd.options.display.float_format='{:,.3f}'.format# Limit output to 3 decimal places.
df.describe()
This will return a table of various statistics such as count, mean, standard deviation and more that will look at bit like this:
FILTERING
When
poking around in your dataset you will often want to take specific a
sample of your data, for example if you had a questionnaire on job
satisfaction, you might want to take all the people in a specific
industry or age range.
Pandas gives us many ways to filter our data to extract the information we want.
Sometimes you’ll want to extract a whole column. Using column labels this is extremely easy.
1
2
# Getting a column by label
df['rain_octsep']
Note
that when we extract a column, we are given back a series, not a
dataframe. If you remember, you can think of a dataframe as a dictionary
of series, so if we pull out a column, of course we get a series back.
Remember
how I pointed out my choice in naming the column labels? Not using
spaces or dashes etc. allows us to access columns the same way we can
access object properties; using a dot.
1
2
# Getting a column by label using .
df.rain_octsep
This will return exactly the same as the previous example. A series of the data in our chosen column.
If you have read the Numpy
post in the series, you may remember a technique called ‘boolean
masking’ and how we can get an array of boolean values running a
conditional on an array. Well we can do this in Pandas too.
1
2
# Creating a series of booleans based on a conditional
df.rain_octsep<1000# Or df['rain_octsep] < 1000
The
above code will return a dataframe of boolean values; ‘True’ if the
rain in October-September what less than 1000mm and ‘False’ if not.
We can then use these conditional expressions to filter an existing dataframe.
1
2
# Using a series of booleans to filter
df[df.rain_octsep<1000]
This will return a dataframe of only entries that had less than 1000mm of rain from October-September.
You can also filter by multiple conditional expressions.
1
2
# Filtering by multiple conditionals
df[(df.rain_octsep<1000)&(df.outflow_octsep<4000)]# Can't use the keyword 'and'
This will return only the entries that have a value of less than 1000 for rain_octsep and less than 4000 for outflow_octsep.
An
important thing to note here is you cannot use the keyword ‘and’ here
due to problems with the order of operations. You must use ‘&’ and
brackets.
If you have strings in your data, then good news for you, you can also use string methods to filter with.
1
2
# Filtering by string methods
df[df.water_year.str.startswith('199')]
Note
that you have to use .str.[string method], you can’t just call a string
method on it right away. This returns all entries in the 1990’s.
INDEXING
The
previous section showed us how to get data based on operations done to
the columns, but Pandas has labelled rows too. These row labels can be
numerical or label based, and the method of retrieving a row differs
depending on this label type.
If your rows have numerical indices, you can reference them using iloc.
1
2
# Getting a row via a numerical index
df.iloc[30]
iloc
will only work on numerical indices. It will return a series of that
row. Each column of that row will be an element in the returned series.
Maybe
in your dataset you have a column of years, or ages. Maybe you want to
be able to reference rows using these years or ages. In this case we can
set a new index (or multiple).
1
2
3
# Setting a new index from an existing column
df=df.set_index(['water_year'])
df.head(5)
This
will make the column ‘water_year’ an index. Notice that the column name
is actually in a list, although the one above only has one element. If
you wanted to have more than one index, this can be easily done by
adding another column name to the list.
In
the above example we set our index to be a column that is full of
strings. This means that we now can’t reference then with iloc, so what
do we use? We use loc.
1
2
# Getting a row via a label-based index
df.loc['2000/01']
This,
like iloc will return a series of the row you reference. The only
difference is this time you are using label based referencing not
numerical based.
There is another commonly used way to reference a
row; ix. So if loc is label based and iloc is numerical based… What is
ix? Well, ix is label based with a numerical index fallback.
1
2
# Getting a row via a label-based or numerical index
df.ix['1999/00']# Label based with numerical index fallback *Not recommended
Just like loc and iloc this will return a series of the row you referenced.
So
if ix does the job of both loc and iloc, why would you use anything
else? The big reason is that it is slightly unpredictable. Remember how I
said that it is label based with a numerical index fallback? Well this
makes it do weird things sometimes like interpreting a number as a
location. Using loc and iloc gives you safety, predictability, peace of
mind. I should point out however, that ix is faster than both loc and
iloc
It’s often useful to have indexes in order, we can do this in pandas via calling sort_index on our dataframe.
1
df.sort_index(ascending=False).head(5)#inplace=True to apple the sorting in place
My
index is already in order, so I set the keyword argument ‘ascending’ to
False for demonstration purposes. This makes my data sort in descending
order.
When
you set a column of data to an index, it is no longer data per se. If
you want to return the index to it’s original data form you just do the
opposite of set_index… reset_index.
1
2
3
# Returning an index to data
df=df.reset_index('water_year')
df.head(5)
This will return your index to it’s original column form.
APPLYING FUNCTIONS TO DATASETS
Sometimes
you will want to change or operate on the data in your dataset in some
way. For example maybe you have a list of years and want to create a new
column that gives the year’s decade. Pandas has two very useful
functions for this, apply and applymap.
1
2
3
4
5
6
7
8
# Applying a function to a column
def base_year(year):
base_year=year[:4]
base_year=pd.to_datetime(base_year).year
returnbase_year
df['year']=df.water_year.apply(base_year)
df.head(5)
This
creates a new column called ‘year’ that is derived from the
‘water_year’ column and extracts just the main year. This is how to use
apply, which is how you apply a function to a column. If you wanted to
apply some function to the whole dataset you can use dataset.applymap().
MANIPULATING A DATASET’S STRUCTURE
Another common thing to do with dataframes is to restructure them in order to put them in a more convenient and/or useful form.
The
easiest way to get to grips with these transformations is to see them
happening, more than anything else in this post, the next few operations
require some playing with to get your head around them.
First up, groupby…
1
2
3
#Manipulating structure (groupby, unstack, pivot)
# Grouby
df.groupby(df.year// 10 * 10).max()
What
grouby does is form groups around the column you choose. Above groups
by decade. This however doesn’t produce anything useful to us, we must
then call something on it, such as max, min, mean, etc. Which will give
us for example, the mean x in the 90’s.
Next
up unstacking which can be a little confusing at first. What it does is
push a column up to become column labels. It’s best to just see it in
action…
1
2
# Unstacking
decade_rain.unstack(0)
This
transforms the dataframe that we produced in the section above into the
dataframe below. It pushes up the 0th column, which is actually the
index ‘year’, and turns it into column labels.
Let’s do one more for good measure. This time on the 1st column, which is the index ‘rain_octsep’.
1
2
# More unstacking
decade_rain.unstack(1)
Now before our next operation, we will first create a new dataframe to play with.
1
2
3
4
# Create a new dataframe containing entries which
# has rain_octsep values of greater than 1250
high_rain=df[df.rain_octsep>1250]
high_rain
The above code gives us the below dataframe which we will perform pivoting on.
Pivoting
is actually a combination of operations that we have already looked at
in this post. First it sets a new index (set_index()), then it sorts
that index (sort_index()) and finally it does an unstack on it. Together
this is a pivot. See if you can visualise what is happening.
Notice
at the end there is a .fillna(”). This pivot creates a lot of empty
entries, NaN value entries. I personally find my dataframe being
littered with NaNs distracting so I use fillna(”). You can enter
whatever you like, for example a zero. We can also use the function
dropna(how=’any’) to delete all rows with NaNs in them. In this case it
would delete everything though, so we won’t do that.
The
above dataframe shows us the outflow for all the years with rainfall
over 1250. Admittedly this wasn’t the best example of a pivot in terms
of practical use, but hopefully you get the idea. See what you can come
up with in your dataset.
COMBINING DATASETS
Sometimes you
will have two separate datasets that relate to each other that you want
to compare them together or combine them. Well, no problem; Pandas makes
this easy.
First
off you need to have matching columns to merge on which you can then
select via the ‘on’ keyword argument. You can often omit it and Pandas
will work out one which columns to merge too.
As you can see
below, the two datasets have been combined on the year category. The
rain_jpn dataset only has the year and amount of rainfall and as we
merged on the year column, only one column ‘jpn_rainfall’ has been
merged with the columns from our UK rain dataset.
USING PANDAS TO PLOT GRAPHS QUICKLY
Matplotlib
is great, but it takes a fair bit of code to create a half-way decent
graph and sometimes you just want to quickly whip up a plot of your data
for just your eyes to help you explore and make sense of it. Pandas
answers this problem with plot.
This
creates a plot of your data using matplotlib, quickly and hassle free.
From this you can then analyse your data visually to give yourself more
direction when exploring. For example if you look at the plot of my
data, you can see that maybe there was a drought in UK in 1995.
You can also see that UK’s rainfall is significantly less than Japan’s, and people say UK rains a lot!
SAVING YOUR DATASETS
After
cleaning, reshaping and exploring your dataset, you often end up with
something very different and much more useful than what you started
with. You should also ways keep your original data, but also saving your
newly polished dataset is a good idea too.
1
2
# Saving your data to a csv
df.to_csv('uk_rain.csv')
The above code will save your data to a csv ready for next time.
So
there we have it, and introduction to Pandas. As I said before, Pandas
is really great and we have only scratched the surface here, but you
should now know enough to get going and start cleaning and exploring
data.
As usual I really urge you to go and play with this. Find a
dataset or two that really interests you, sit down with a beer maybe and
start probing it. It’s really the only way to get comfortable with
Pandas and the other libraries introduced in this series. Plus you never
know, you might find something interesting.
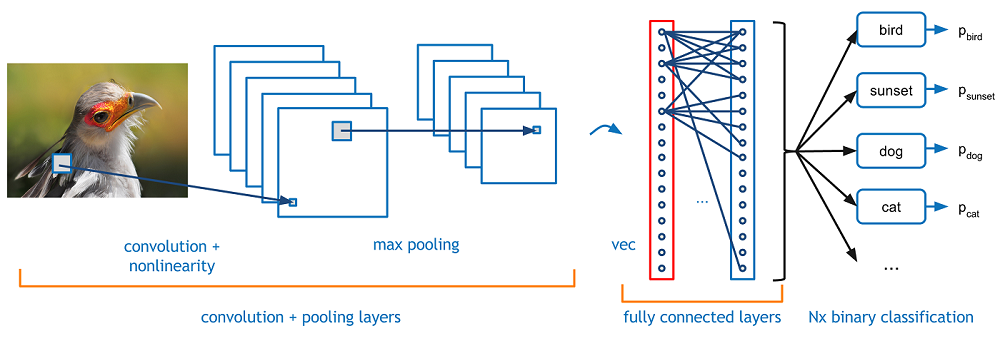
 However, the classic, and arguably most popular, use case of these
networks is for image processing. Within image processing, let’s take a
look at how to use these CNNs for image classification.
However, the classic, and arguably most popular, use case of these
networks is for image processing. Within image processing, let’s take a
look at how to use these CNNs for image classification.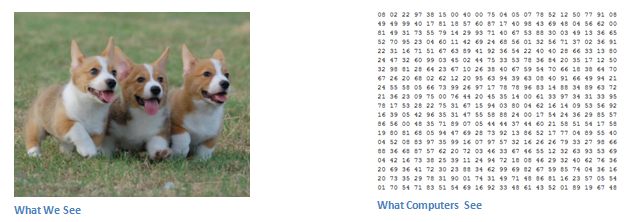
 Let’s say now we use two 5 x 5 x 3 filters instead of one. Then our
output volume would be 28 x 28 x 2. By using more filters, we are able
to preserve the spatial dimensions better. Mathematically, this is
what’s going on in a convolutional layer.
Let’s say now we use two 5 x 5 x 3 filters instead of one. Then our
output volume would be 28 x 28 x 2. By using more filters, we are able
to preserve the spatial dimensions better. Mathematically, this is
what’s going on in a convolutional layer.