https://blog.nanonets.com/hyperparameter-optimization/
So you’ve watched all the tutorials. You now understand how a neural network works. You’ve built a cat and dog classifier. You tried your hand at a half-decent character-level RNN. You’re just one
pip install tensorflow away from building the terminator, right? Wrong.
In this article, I’ll walk you through some of the most common (and important) hyperparameters that you’ll encounter on your road to the #1 spot on the Kaggle leaderboards. In addition, I’ll also show you some powerful algorithms that can help you choose your hyperparameters wisely.
Hyperparameters in Deep Learning
Hyperparameters can be thought of as the tuning knobs of your model.A fancy 7.1 Dolby Atmos home theatre system with a subwoofer that produces bass beyond the human ear’s audible range is useless if you set your AV receiver to stereo.

So now, let's take a look at the knobs to tune before we get into how to dial in the right settings.
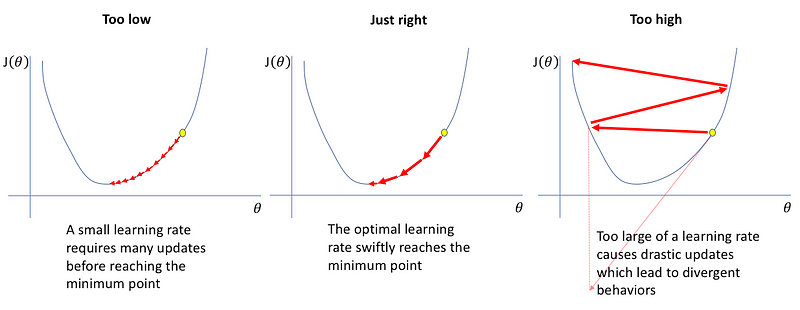
Learning Rate
Arguably the most important hyperparameter, the learning rate, roughly speaking, controls how fast your neural net “learns”.So why don’t we just amp this up and live life on the fast lane?

Momentum
Since this article focuses on hyperparameter optimization, I’m not going to explain the whole concept of momentum. But in short, the momentum constant can be thought of as the mass of a ball that’s rolling down the surface of the loss function.The heavier the ball, the quicker it falls. But if it’s too heavy, it can get stuck or overshoot the target.

Dropout
If you’re sensing a theme here, I’m now going to direct you to Amar Budhiraja’s article on dropout.
is a hyperparameter.
Architecture — Number of Layers, Neurons Per Layer, etc.
Another (fairly recent) idea is to make the architecture of the neural network itself a hyperparameter.Although we generally don’t make machines figure out the architecture of our models (otherwise AI researchers would lose their jobs), some new techniques like Neural Architecture Search have been implemented this idea with varying degrees of success.
If you’ve heard of AutoML, this is basically how Google does it: make everything a hyperparameter and then throw a billion TPUs at the problem and let it solve itself.
But for the vast majority of us who just want to classify cats and dogs with a budget machine cobbled together after a Black Friday sale, it’s about time we figured out how to make those deep learning models actually work.
Hyperparameter Optimization Algorithms
Grid Search
This is the simplest possible way to get good hyperparameters. It’s literally just brute force.The Algorithm: Try out a bunch of hyperparameters from a given set of hyperparameters, and see what works best.
Try it in a notebookThe Pros: It’s easy enough for a fifth grader to implement. Can be easily parallelized.
The Cons: As you probably guessed, it’s insanely computationally expensive(as all brute force methods are).
Should I use it: Probably not. Grid search is terribly inefficient. Even if you want to keep it simple, you’re better off using random search.
Random Search
It’s all in the name — random search searches. Randomly.The Algorithm: Try out a bunch of random hyperparameters from a uniform distribution over some hyperparameter space, and see what works best.
Try it in a notebookThe Pros: Can be easily parallelized. Just as simple as grid search, but a bit better performance, as illustrated below:

Should I use it: If trivial parallelization and simplicity are of utmost importance, go for it. But if you can spare the time and effort, you'll be rewarded big time by using Bayesian Optimization.
Bayesian Optimization
Unlike the other methods we’ve seen so far, Bayesian optimization uses knowledge of previous iterations of the algorithm. With grid search and random search, each hyperparameter guess is independent. But with Bayesian methods, each time we select and try out different hyperparameters, the inches toward perfection.
Remember, the reason we’re using these hyperparameter tuning algorithms is that it’s infeasible to actually evaluate multiple hyperparameter choices individually. For example, let’s say we wanted to find a good learning rate manually. This would involve setting a learning rate, training your model, evaluating it, selecting a different learning rate, training you model from scratch again, re-evaluating it, and the cycle continues.
The problem is, “training your model” can take up to days (depending on the complexity of the problem) to finish. So you would only be able to try a few learning rates by the time the paper submission deadline for the conference turns up. And what do you know, you haven’t even started playing with the momentum. Oops.

As an example, say we want to minimize this function (think of it like a proxy for your model's loss function):

Which, admittedly is a mouthful. But let’s try to break it down.
The left-hand side is telling you that a probability distribution is involved (given the presence of the fancy looking ). Looking inside the brackets, we can see that it’s a probability distribution of , which is some arbitrary function. Why? Because remember, we’re defining a probability distribution over allpossible functions, not just a particular one. In essence, the left-hand side says that the probability that the true function that maps hyperparameters to the model’s metrics (like validation accuracy, log likelihood, test error rate, etc.) is , given some sample data is equal to whatever’s on the right-hand side.
Now that we have the function to optimize, we optimize it.
Here's what the Gaussian process will look like before we start the optimization process:

After a few iterations, the Gaussian process gets better at approximating the target function:

The final result should look like this:

Try it in a notebookThe Pros: Bayesian optimization gives better results than both grid search and random search.
The Cons: It's not as easy to parallelize.
Should I Use It: In most cases, yes! The only exceptions would be if
- You're a deep learning expert and you don't need the help of a measly approximation algorithm.
- You have access to a vast computational resources and can massively parallelize grid search and random search.
- If you're an frequentist/anti-Bayesian statistics nerd.
An Alternate Approach To Finding A Good Learning Rate
In all the methods we’ve seen so far, there’s one underlying theme: automate the job of the machine learning engineer. Which is great and all; until your boss gets wind of this and decides to replace you with 4 RTX Titan cards. Huh. Guess you should have stuck to manual search.
The paper is actually about a method for scheduling (changing) the learning rate over time. The LR (learning rate) range test was a gold nugget that the author just casually dropped on the side.
When you’re using a learning rate schedule that varies the learning rate from a minimum to maximum value, such as cyclic learning rates or stochastic gradient descent with warm restarts, the author suggests linearly increasing the learning rate after each iteration from a small to a large value (say,
1e-7 to 1e-1),
evaluate the loss at each iteration, and plot the loss (or test error
or accuracy) against the learning rate on a log scale. Your plot should
look something like this: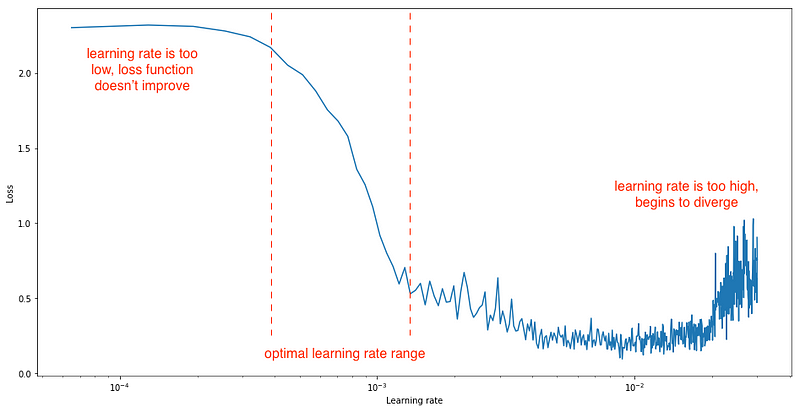
Here's a sample LR range test plot (DenseNet trained on CIFAR10) from our Colab notebook:

1e-2.The coolest part about this method, other than that it works really well and spares you the time, mental effort, and compute required to find good hyperparameters with other algorithms, is that it costs virtually no extra compute.
While the other algorithms, namely grid search, random search, and Bayesian Optimization, require you to run a whole project tangential to your goal of training a good neural net, the LR range test is just executing a simple, regular training loop, and keeping track of a few variables along the way.
Here's the type of convergence speed you can expect when using a optimal learning rate (from the example in the notebook):

For The More Sophisticated Deep Learning Practitioner
If you're interested, there's also a notebook written in pure pytorch that implements the above. This might give you a better understanding of the behind-the-scenes training process. Check it out here.Save Yourself The Effort

Nanonets provides easy to use APIs to train and deploy custom deep learning models. It takes care of all of the heavy lifting, including data augmentation, transfer learning and yes, hyperparameter optimization!
Nanonets makes use of Bayesian search on their vast GPU clusters to find the right set of hyperparameters without the need for you to worry about blowing cash on the latest graphics card and
out of bounds for axis 0.Once it finds the best model, Nanonets serves it on their cloud for you to test the model using their web interface or to integrate it into your program using 2 lines of code.
Say goodbye to less than perfect models.
Conclusion
In this article, we’ve talked about hyperparameters and a few methods of optimizing them. But what does it all mean?As we try harder and harder to democratize AI technology, automated hyperparameter tuning is probably a step in the right direction. It allows regular folks like you and me to build amazing deep learning applications without a math PhD.
While you could argue that making model hungry for computing power leaves the very best models in the hands of those that can afford said computing power, cloud services like AWS and Nanonets help democratize access to powerful machines, making deep learning far more accessible.
But more fundamentally, what we’re actually doing here using math to solve more math. Which is interesting not only because of how meta that sounds, but also because of how easily it can be misinterpreted.

And that's not discouraging, not in the least, because if humanity can do so much with so little, imagine what the future holds, when our visions become something that we can actually see.
And so we sit, on a cushioned mesh chair staring at a blank terminal screen, every keystroke giving us a
sudo superpower that can wipe the disk clean.And so we sit, we sit there all day, because the next big breakthrough might be just one
pip install away.
No comments:
Post a Comment