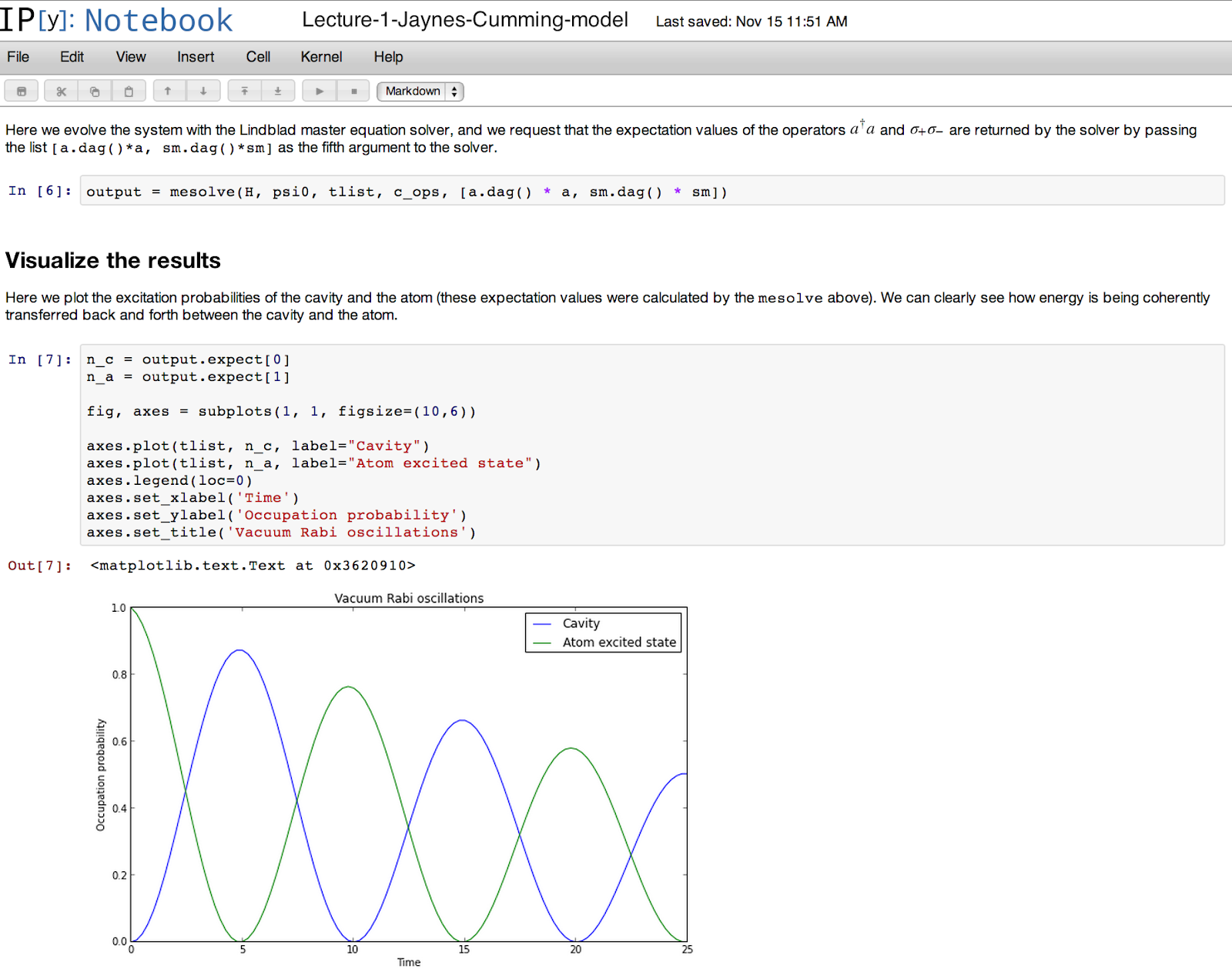
I have been using GPUs for nearly two years now and for me it is again and again amazing to see how much speedup you get. Compared to CPUs 20x speedups are typical, but on larger problems one can achieve 50x speedups. With GPUs you can try out new ideas, algorithms and experiments much faster than usual and get almost immediate feedback as to what works and what does not. This is a very important aspect when one begins to learn deep learning as this rapid gain in practical experience is key to building the expertise with which you will be able to apply deep learning to new problems. Without this rapid feedback it just takes too much time to learn from one’s mistakes and it can be discouraging and frustrating to go on with deep learning.
With GPUs I quickly learned how to apply deep learning on a range of Kaggle competitions and I managed to earn second place in the Partly Sunny with a Chance of Hashtags Kaggle competition, where it was the task to predict weather ratings for a given tweet. In the competition I used a rather large two layered deep neural network with rectified linear units and dropout for regularization and this deep net fitted barely into my 6GB GPU memory. More details on my approach can be found here.
Should I get multiple GPUs?
Excited by what deep learning can do with GPUs I plunged myself into
multi-GPU territory by assembling a small GPU cluster with InfiniBand
40Gbit/s interconnect. I was thrilled to see if even better results can
be obtained with multiple GPUs.I quickly found that it is not only very difficult to parallelize neural networks on multiple GPU efficiently, but also that the speedup was only mediocre for dense neural networks. Small neural networks could be parallelized rather efficiently using data parallelism, but larger neural networks like I used in the Partly Sunny with a Chance of Hashtags Kaggle competition received almost no speedup.