One
of the main ML problems is text classification, which is used, for
example, to detect spam, define the topic of a news article, or choose
the correct mining of a multi-valued word. The Statsbot team has already written how to train your own model for detecting spam emails, spam messages, and spam user comments. For this article, we asked a data scientist, Roman Trusov, to go deeper with machine learning text analysis.
You
may know it’s impossible to define the best text classifier. In fields
such as computer vision, there’s a strong consensus about a general way
of designing models − deep networks with lots of residual connections.
Unlike that, text classification is still far from convergence on some
narrow area.
In this article, we’ll focus on the few main generalized approaches of text classifier algorithms
and their use cases. Along with the high-level discussion, we offer a
collection of hands-on tutorials and tools that can help with building
your own models.
Text Classification Benchmarks
The
toolbox of a modern machine learning practitioner who focuses on text
mining spans from TF-IDF features and Linear SVMs, to word embeddings
(word2vec) and attention-based neural architectures.
It’s important to distinguish two cases when the effectiveness of a certain method is demonstrated: research and competition.
When
researchers compare the text classification algorithms, they use them
as they are, probably augmented with a few tricks, on well-known
datasets that allow them to compare their results with many other
attempts on the same problem.
Some well-known text classification benchmarks:
- AG’s news articles
- Sogou news corpora
- Amazon Review Full
- Amazon Review Polarity
- DBPedia
- Yahoo Answers
- Yelp Review Full
- Yelp Review Polarity
We’ve made a special folder on google drive so you could download them right away.
Deep vs. Shallow Learning
The
really remarkable thing about the datasets widely adopted in NLP
research is that both simple and very complex models work on them very
well. To showcase this, let’s discuss two papers:
- A Bag of Tricks for Efficient Text Classification by Joulin et al
- Character-level Convolutional Networks for Text Classification by Zhang et al
The
datasets in both cases are the same, and the results in terms of
precision are roughly the same across all the experiments. But the
training and inference time varies greatly between the two.
The
first model takes literally seconds to train, while the second needs
several hours, which would be a game changer when it comes to choosing
the hyperparameters.
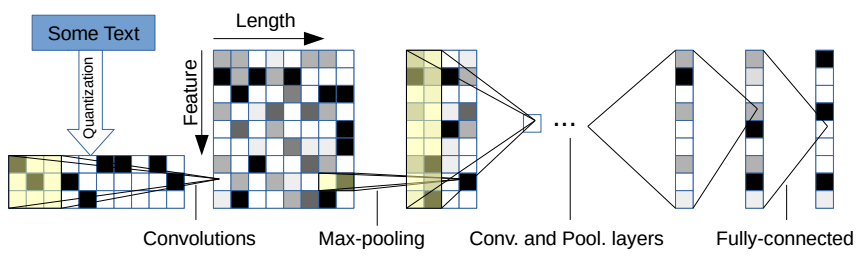
What
makes this approach interesting is that their model doesn’t make any
assumptions about the data. At the lowest level they treat the text as a
sequence of characters, allowing the convolutional layers to build the
features in a completely content-agnostic way.
The
second paper features a much lighter model that’s designed to work fast
on a CPU and consists of a joint embedding layer and a softmax
classifier.
On the other hand, if you take a look at some of the winning solutions on Kaggle, you’ll see they are dominated by highly customized complex ensembles.
A good example would be the recent Quora Question Pairs competition and ongoing DeepHack.Turing, where top-ranking solutions consist of several different models: gradient boosting machines, RNNs, and CNNs.
The practical lesson we can learn here
is that despite the results of certain methods published in research,
getting the best performance from the particular tasks in vivo is closer
to art than to science, requiring careful tuning of complicated
pipelines.
The striking contrast with the research here can be seen in a writeup for a winning solution on Kaggle.
Neural network-based text classifiers typically follow the same linear meta architecture:
- Embedding
- Deep representation
- Fully connected part
Embedding
Embedding
layers take a sequence of word ids as an input and produce a sequence
of corresponding vectors as an output. Their functionality is really
straightforward, and since the actual semantics of those vectors are not
interesting for our problem, the only remaining question is “What is
the best way to initialize the weights?”
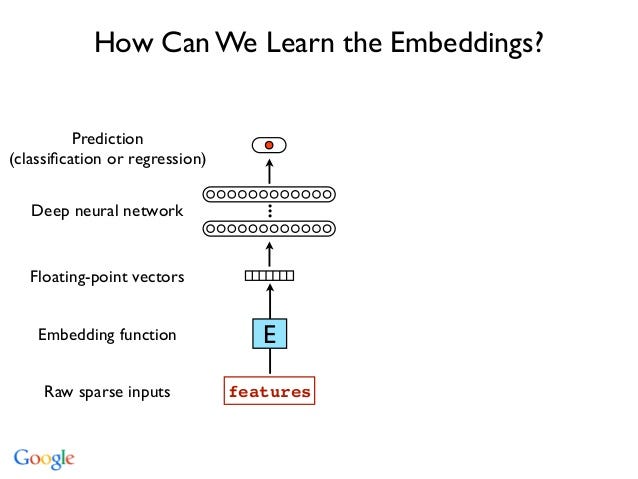
Depending
on the problem, the answers may be as counterintuitive as the advice
“generate your own synthetic labels, train word2vec on them, and init
the embedding layer with them.”
But
for all practical purposes you can use a pre-trained set of embeddings
and jointly fine-tune it for your particular model. It’s likely that
resulting word vectors will cease to demonstrate the same properties as
they do in a vanilla word2vec model:
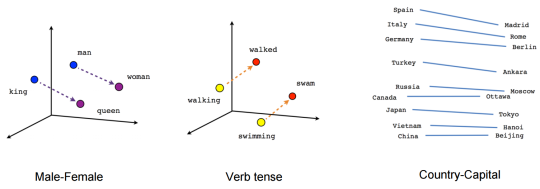
But it doesn’t matter in this case.
The
go-to solution here is to use pretrained word2vec embeddings and try to
use lower learning rates for the embedding layer (multiply general
learning rate by 0.1).
Deep representation
The main purpose of the deep representation
part is to condense all relevant information in its output while
suppressing the parts that could lead to identifying a single sample
from it. This is highly desirable because the network with high capacity
is likely to overfit on particular examples and perform poorly on the
test set.
Recurrent neural network (RNN)
When
the problem consists of obtaining a single prediction for a given
document (spam/not spam), the most straightforward and reliable
architecture is a multilayer fully connected text classifier
applied to the hidden state of a recurrent network. Semantics of this
state are considered irrelevant, and the entire vector is treated as a
compressed description of the text.
Here are several useful sources:
• A great starting point for understanding how to use LSTMs for text classification (in this case — sentiment analysis).
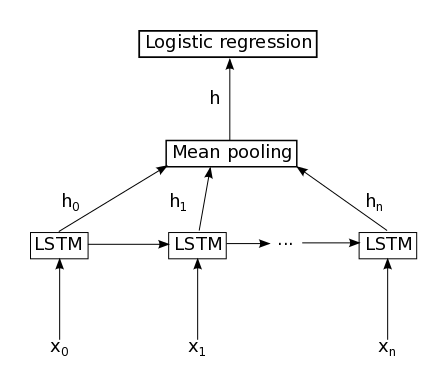
Since
the main work is being done in the recurrent layer, it’s important to
make sure that it captures only the relevant information. It’s a
frequent challenge for natural language applications and an open
scientific problem.
On a high level, there are two things that can be done here:
- Use Bidirectional LSTMs. This is almost always a good idea, because it essentially captures the context around each word, instead of sequential “reading.”
- Use a transitional layer for embeddings. LSTMs learn to distinguish important and unimportant parts of the sequence by themselves, but we can’t be sure that the representation from the embedding layer is the best input, especially if we don’t finetune the embeddings. Adding a layer that’s applied to each word embedding independently can improve your results, acting as a simple attention layer.
Convolutional neural network (CNN)
An alternative way to train a deep text classifier is to use convolutional networks.
Typically, given a large enough receptive field, you can achieve the
same results as with a dedicated attention layer. There’s no single
trick here, but keeping a lot of feature maps in the beginning and
reducing their number exponentially later helps to avoid learning
irrelevant patterns.
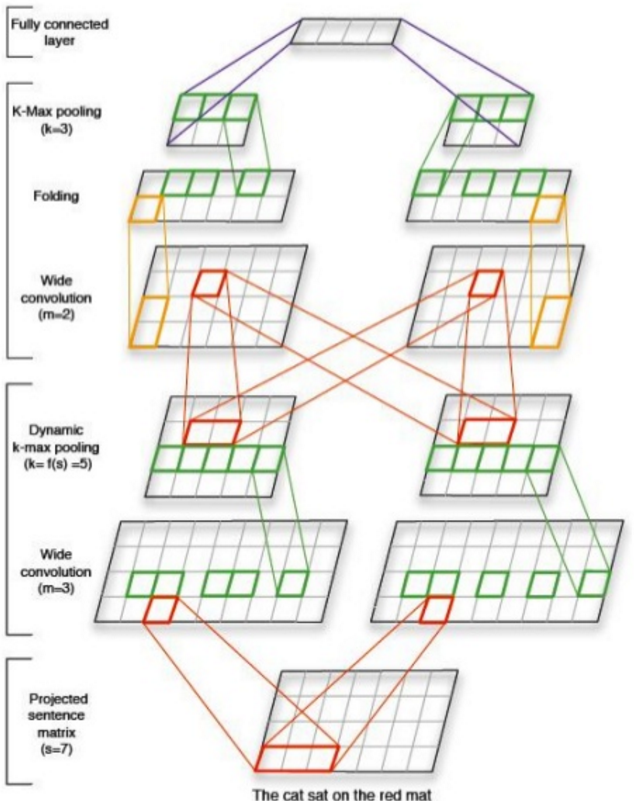
Take a look at this simple implementation of CNN classifier in PyTorch. It shows how to train and evaluate a convolutional classifier with its own embedding layer.
Dense Classifier
A fully-connected part
performs a series of transformations on the deep representation and
finally outputs the scores for each class. The best practice here is to
apply the transformations as follows:
- Fully-connected layer
- Batch normalization
- (Optional) Non-linear transformation (hyperbolic tangent or ELU)
- Dropout
I
hope you like this overview of neural text classifier algorithms that
can be further augmented with more sophisticated methods of your choice.
A few tips and tricks mentioned here are going to help you with
building better models and achieving faster convergence.
In addition, below you’ll find a few links to tutorials and tools for classification and representation learning tasks.
Helpful resources
- A collection of tools and implemented ready-to-train text classifiers (PyTorch)
- FastText, a library for efficient text classification and building word representations
- Skip-gram tutorial: part 1, part 2
- CNN text classifier in TensorFlow
- RNN Sentence classification tutorial in Keras
No comments:
Post a Comment