Bootstrapping/Bagging/Boosting
Machine learning and data science require more than just throwing data into a python library and utilizing whatever comes out.
Data
scientists need to actually understand the data and the processes
behind the data to be able to implement a successful system.
One
key methodology to implementation is knowing when a model might benefit
from utilizing bootstrapping methods. These are what are called
ensemble models. Some examples of ensemble models are AdaBoost and
Stochastic Gradient Boosting.
Why use ensemble models?
They
can help improve algorithm accuracy or improve the robustness of a
model. Two examples of this is boosting and bagging. Boosting and
Bagging are must know topics for data scientists and machine learning
engineers. Especially if you are planning to go in for a data science/machine learning interview.
Essentially,
ensemble learning follows true to the word ensemble. Except, instead of
having several people who are singing at different octaves to create
one beautiful harmony (each voice filling in the void of the other).
Ensemble learning uses hundreds to thousands of models of the same
algorithm that work together to find the correct classification.
Another way to think about ensemble learning is the fable of the blind men and the elephant.
Where each blind man found a feature of the elephant and they all
thought it was something different. However, had they come together and
discussed it, they might have been able to figure out what they were
looking at.
Using techniques like boosting and bagging has lead to increased robustness of statistical models and decreased variance.
Now the question becomes, with all these different “B” words. What is the difference?
Bootstrapping
Let’s
first talk about the very important concept of bootstrapping. This can
occasionally be missed as many data scientists will go straight to
explaining boosting and bagging. Both of which require bootstrapping.
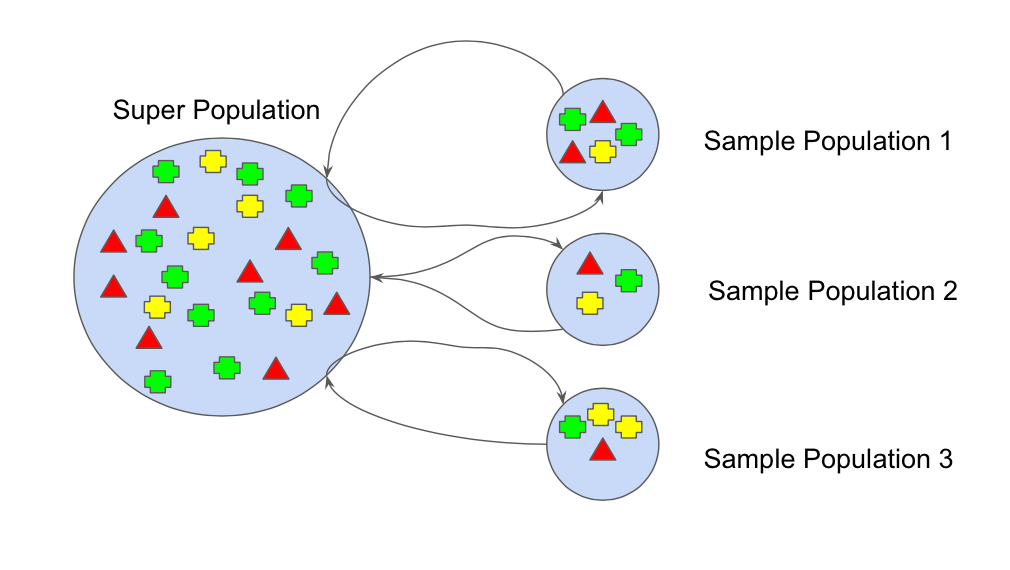
In machine learning, the bootstrap method refers to random sampling with replacement.
This sample is referred to as a resample. This allows the model or
algorithm to get a better understanding of the various biases, variances
and features that exist in the resample. Taking a sample of the data
allows the resample to contain different characteristics then it might
have contained as a whole. Demonstrated in figure 1 where each sample
population has different pieces, and none are identical. This would then
affect the overall mean, standard deviation and other descriptive
metrics of a data set. In turn, it can develop more robust models.
Bootstrapping is also great for small size data sets that can have a tendency to overfit. In fact, we recommended this to one company who was concerned because their data sets were far from “Big Data”.
Bootstrapping can be a solution in this case because algorithms that
utilize bootstrapping can be more robust and handle new data sets
depending on the methodology chosen(boosting or bagging)
The
reason to use the bootstrap method is because it can test the stability
of a solution. By using multiple sample data sets and then testing
multiple models, it can increase robustness. Perhaps one sample data set
has a larger mean than another, or a different standard deviation. This
might break a model that was overfit, and not tested using data sets
with different variations.
One
of the many reasons bootstrapping has become very common is because of
the increase in computing power. This allows for many times more
permutations to be done with different resamples than previously.
Bootstrapping is used in both Bagging and Boosting, as will be discussed
below.
Bagging
Bagging
actually refers to (Bootstrap Aggregators). Most any paper or post that
references using bagging algorithms will also reference Leo Breiman who
wrote a paper in 1996 called “Bagging Predictors”.
Where Leo describes bagging as:
“Bagging predictors is a method for generating multiple versions of a predictor and using these to get an aggregated predictor.”
What Bagging does is help reduce variance from models that are might be very accurate, but only on the data they were trained on. This is also known as overfitting.
Overfitting
is when a function fits the data too well. Typically this is because
the actual equation is much too complicated to take into account each
data point and outlier.
Another example of an algorithm that can overfit easily is a decision tree. The models that are developed using decision trees require very simple heuristics.
Decision trees are composed of a set of if-else statements done in a
specific order. Thus, if the data set is changed to a new data set that
might have some bias or difference in spread of underlying features
compared to the previous set. The model will fail to be as accurate.
This is because the data will not fit the model as well(which is a
backwards statement anyways).
Bagging gets around this by creating it’s own variance amongst the data by sampling and replacing data
while it tests multiple hypothesis(models). In turn, this reduces the
noise by utilizing multiple samples that would most likely be made up of
data with various attributes(median, average, etc).
Once each model has developed a hypothesis. The models use voting for classification or averaging for regression.
This is where the “Aggregating” in “Bootstrap Aggregating” comes into
play. Each hypothesis has the same weight as all the others. When we later discuss boosting, this is one of the places the two methodologies differ.
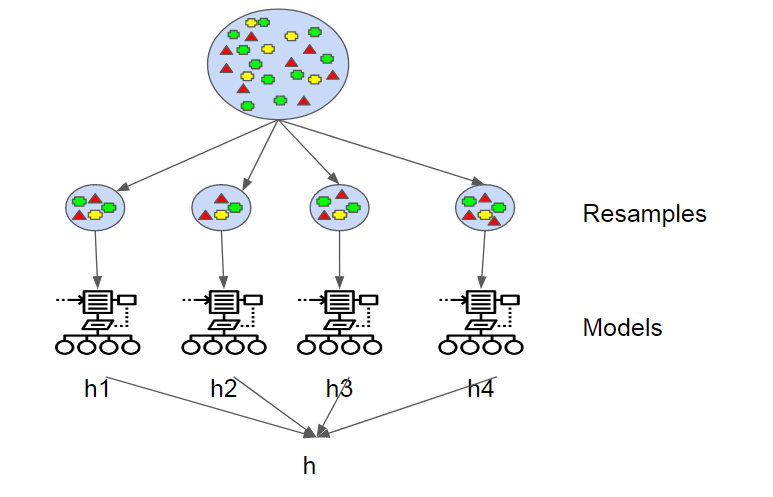
Essentially, all these models run at the same time, and vote on which hypothesis is the most accurate.
This helps to decrease variance i.e. reduce the overfit.
Boosting
Boosting
refers to a group of algorithms that utilize weighted averages to make
weak learners into stronger learners. Unlike bagging that had each model
run independently and then aggregate the outputs at the end without
preference to any model. Boosting is all about “teamwork”. Each model
that runs, dictates what features the next model will focus on.
Boosting
also requires bootstrapping. However, there is another difference here.
Unlike in bagging, boosting weights each sample of data. This means
some samples will be run more often than others.
Why put weights on the samples of data?
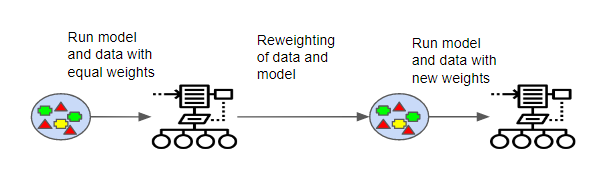
When
boosting runs each model, it tracks which data samples are the most
successful and which are not. The data sets with the most misclassified
outputs are given heavier weights. These are considered to be data that
have more complexity and requires more iterations to properly train the
model.
During
the actual classification stage, there is also a difference in how
boosting treats the models. In boosting, the model’s error rates are
kept track of because better models are given better weights.
That way, when the “voting” occurs, like in bagging, the models with better outcomes have a stronger pull on the final output.
Summary
Boosting
and bagging are both great techniques to decrease variance. Ensemble
methods generally out perform a single model. This is why many of the
Kaggle winners have utilized ensemble methodologies. One that was not
discussed here was stacking. However, that requires it’s own post.
However,
they won’t fix every problem, and they themselves have their own
problems. There are different reasons you would use one over the other.
Bagging is great for decreasing variance when a model is overfit.
However, boosting is much more likely to be a better pick of the two
methods. Boosting also is much more likely to cause performance issues.
It is also great for decreasing bias in an underfit model.
This
is where experience and subject matter expertise comes in! It can be
easy to jump on the first model that works. However, it is important to analyze the algorithm
and all the features it selects. For instance, if a decision tree sets
specific leafs, the question becomes, why! If you can’t support it with
other data points and visuals, it probably shouldn’t be implemented.
It
is not just about trying AdaBoost, or Random forests on various data
sets. Depending on the results an algorithm is getting, and what support
is there, drives the final algorithm
Call To Action
Do
you need a team of experienced data specialist to come in and help
develop a data driven team or design and integrate a new system? Reach out to our team today!
Are you interested in learning more about data science and machine learning?
This article is slightly modified from my original which can be found here!
No comments:
Post a Comment