Open Sourcing the New C++ Implementation
We are pleased to announce the open sourcing of nGraph, a framework-neutral Deep Neural Network (DNN) model compiler that can target a variety of devices. With nGraph, data scientists can focus on data science rather than worrying about how to adapt their DNN models to train and run efficiently on different devices. Continue reading below for highlights of our engineering challenges and design decisions, and see GitHub, our documentation, and our SysML paper for additional details.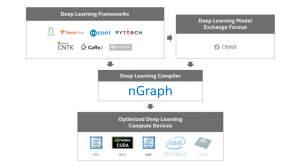
Figure 1 – nGraph ecosystem.
We currently support TensorFlow*, MXNet*, and neon directly through nGraph. CNTK*, PyTorch*, and Caffe2* are supported indirectly through ONNX. Users can run these frameworks on several devices: Intel Architecture, GPU, and Intel Nervana Neural Network Processor (NNP). Support for future devices/frameworks in our roadmap is faded.
Why did we build nGraph?
When Deep Learning (DL) frameworks first emerged as the vehicle for running training and inference models, they were designed around kernels optimized for a particular device. As a result, many device details were being exposed in the model definitions, complicating the adaptability and portability of DL models to other, or more advanced, devices.The traditional approach means that an algorithm developer faces tediousness in taking their model to an upgraded device. Enabling a model to run on a different framework is also problematic because the developer must separate the essence of the model from the performance adjustments made for the device, translate to similar ops in the new framework, and finally make the necessary changes for the preferred device configuration on the new framework.
We designed the nGraph library to substantially reduce these kinds of engineering complexities. While optimized kernels for DL primitives are provided through the project and via libraries like Intel® Math Kernel Library for Deep Neural Networks (Intel® MKL-DNN), there are also several compiler-inspired ways in which performance can be further optimized.
How does it work in practice?
Install the nGraph library and write or compile a framework with the library in order to run training and inference models. Specify nGraph as the framework backend you want to use from the command line on any supported system. Our Intermediate Representation (IR) layer handles all the device abstraction details and lets developers focus on their data science, algorithms and models, rather than on machine code.At a more granular level of detail:
- The nGraph core creates a strongly-typed and device-neutral stateless graph representation of computations. Each node, or op, in the graph corresponds to one step in a computation, where each step produces zero or more tensor outputs from zero or more tensor inputs. Our philosophy is that nGraph ops should serve as building blocks for more complex DNN operations found in DL frameworks. This is balanced by the need for efficient compilation and deriving training computations from inference computations.
- We’ve developed a framework bridge for each supported framework; it acts as an intermediary between the nGraph core and the framework. We currently have bridges for TensorFlow/XLA, MXNet, and ONNX. Since ONNX is only an exchange format, the ONNX bridge is augmented by an execution API.
- A transformer plays a similar role between the nGraph core and the various devices; transformers handle the device abstraction with a combination of generic and device-specific graph transformations. The result is a function that can be executed from the framework bridge. Transformers also allocate and deallocate, as well as read and write tensors under direction of the bridge. We currently have transformers for Intel Architecture, Intel NNP, NVIDIA cuDNN, and additional devices under active development.
Current Performance
Intel has considerable experience with MKL-DNN optimization of frameworks for Intel Architecture. We make use of previous work with the added benefit that optimizations developed for a device benefits all frameworks through nGraph. Framework developers continue to perform their own optimization work. For example, the performance for TensorFlow 1.7+/XLA on Intel Architecture is much better than for TensorFlow 1.3/XLA on Intel Architectures, and this should improve further as more work is put into XLA for Intel Architectures.We present below initial performance data from multiple frameworks that reflects the optimizations done so far on the IA transformer. On the latest Intel Xeon Platinum 8180 processor, in conjunction with MKLDNN v0.13, we are able to meet or greatly exceed the performance of previously optimized frameworks such as MXNet-MKLDNN-CPU (MXNet optimized with MKLDNN) and neon-MKLML-CPU (neon optimized with MKLML). We also deliver better performance than the TensorFlow XLA compiler (TF-XLA-CPU), but there are significantly more optimizations that can be done with XLA both on the default CPU implementation and on nGraph.
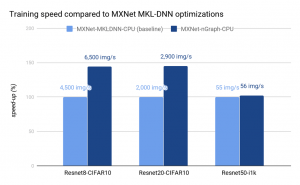
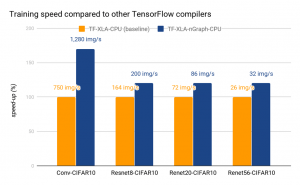

Status and Future Work
As of today, nGraph supports six DL frameworks and three compute devices.Supported frameworks:
- Direct support through nGraph’s framework-independent representation
- TensorFlow*
- MXNet*
- neon
- Indirect support through ONNX
- CNTK*
- PyTorch*
- Caffe2
- Intel Architecture (x86, Intel® Xeon® and Xeon Phi®)
- Intel® Nervana™ Neural Network Processor (Intel® Nervana NNP)
- NVIDIA* cuDNN (in progress)
Visit our GitHub repository to learn how to contribute to nGraph.
No comments:
Post a Comment