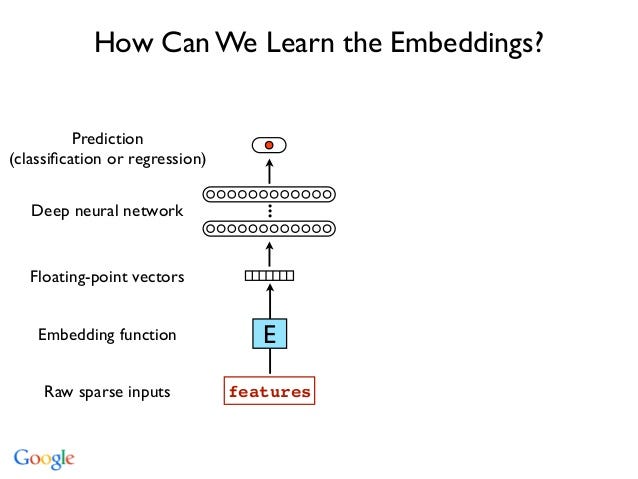
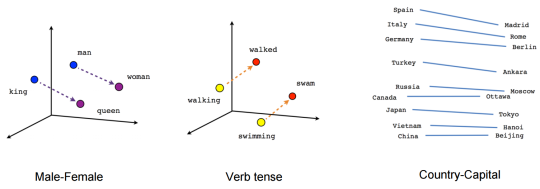
Recent incident where Uber car was involved in an accident where a cyclist got killed has sparked many comments and opinions. Many blame Uber
for incompetent system, others think the accident was trivial to
prevent. I do agree that there is a technology to avoid such accidents.
But I would also like to point out why the problem is not as easy for an
autonomous system to solve as it is for regular city car. So, lets
answer “Mercedes has a night vision system, why Uber did not use one?”
Before I continue I will emphasize that I do not know what was the cause of accident nor do I claim that it was inevitable. In addition I do not want to blame or justify anyone. That said, I will discuss why this problem is much harder for an AI-based system than it is for collision avoidance system in your Seat Ibiza.
Regular collision avoidance (CA) system that can be found in almost any new vehicle is a deterministic and single purpose system.
“Single purpose” means that the system has only one goal — to brake
when the vehicle is about to collide; “deterministic” means that it is
programmed to take certain action (i.e., hit brakes) when certain kind
of signals are detected. It will always produce the same kind of
reaction for the same kind of signal. There are also CA systems that
have some probabilistic behaviour depending on the environment, but in a
large scale, all CA systems are rather straightforward: when the
vehicle approaches something in front of it with unreasonable speed, it
hits the brakes! You can create this system using simple IF-statements
in a program code.
Why is AI-based system different? Artificial intelligence is a capability of a system to demonstrate cognitive skills such as learning and problem solving (see Wikipedia) — AI is not preprogrammed to monitor a known input from a sensor to take a predefined action.
So instead of defining what to do in known circumstances we train AI by
giving the algorithm a lot of data and ask it to learn what to do. This
is machine learning.
If we build a collision avoidance system using machine learning, we’ll
probably achieve near perfect performance — but the system would be
still single purpose system. It would be able to brake but not to
navigate.
Navigation
is composed of sensing and interpreting the environment, making
decisions, and taking action. Environment perception includes path
planning (where to drive?), obstacle detection, and trajectory
estimation (how are detected objects moving?). This is not an exhaustive
list. Now we see that collision avoidance is only one task of the many
and the system has many questions at the same time: where am I going,
what do I see, how to interpret this, are any objects moving, how fast
are they moving, will my trajectory cross with someone else's etc?
Such problem of autonomous navigation is too complex to be solved by using only simple IF-ELSE statements
in program code and map senor signal readings to actions. Why? To
measure everything that is needed for such a task, a vehicle must have
tens of different sensors. The purpose is to have a comprehensive field
of view and to compensate the weaknesses that individual sensors have
(more on that soon). If we now calculate how many different combinations
of measurements these sensors are producing, we’ll clearly see that we
need self-learning system. It is far too complex for a human to model every possible input combination.
Further, this self-learning system will most likely base it’s decisions on probabilities.
If it notices something on the road, it will consider all possible
options and attaches probabilities to each. For example, 5% probability
that the object is a dog and 95.7% probability that it is a lorry will
result in a decision that the object is a lorry. But what if sensor input is contradictory?
This
can easily happen. For example, a normal video camera can see a
reasonably close object in a great detail, but only in two dimensions. A
LIDAR, a kind of laser, will see the same object in three dimensions,
but in less detail and without color information (see the image below).
We can then use several video cameras to reconstruct 3D scene from the
images and compare it with LIDAR “image”. A combined result should be
more trustworthy. But video cameras are sensitive to light
conditions — even a shadow might interfere with some segments of the
scene and produce low quality output. This is where a good system
recognises the difficulty and says that in this situation it will trust
LIDAR output more that video camera output. For some other part of the
scene, the situation might be vice versa. The areas where both sensors agree are where the measurement has the highest quality.
It’s
me sitting on a chair (at the center of the image) waving to the
Velodyne VLP-16 LIDAR at the office. LIDARs that are used on autonomous
cars have somewhat higher resolution, but still far from what a camera
is capable of. Please note that this image is from a single LIDAR scan,
for better resolution image I should accumulate several scans.
What
if camera thinks it is a lorry and LIDAR assesses that it is a dog and
both inputs are trusted equally? This is probably the toughest case
indeed, but far from impossible to solve. Modern CA systems are
operating with memory, they have maps and registers of what they have
seen. They keep track of recorded objects from image to image.
If two seconds ago both sensors (or more precisely, the algorithms that
interprets the sensor readings) agreed the object to be a lorry and now
one of them thinks it’s a dog, it will still be considered a lorry
until there is stronger evidence available. Please keep this example in
mind when we return to the Uber case later.
A
little recap. So far we have covered that an AI must process the input
from many different sensors, it must evaluate both the quality of sensor
input and the quality of constructed understanding of the scene.
Sometimes different sensors give different prediction and not all
sensors are usable at any given time. The system also has a memory which
affects the process, just like for humans. It must then fuse this information to form a single understanding about the situation and use this to drive the car.
What could go wrong, can we trust such AI system? The quality of the system is a combination of its architecture
(which sensors are used, how sensor information is processed, how the
information is fused, which algorithms are used, how decisions are
evaluated etc) and the nature and amount of data that is used to train it.
Even with perfect architecture, many things could go wrong if we have
too few data. It is like sending unexperienced worker to execute a
difficult task. More data means more chances to learn and leads to
better decisions. Unlike humans, an AI can pool hundreds of years worth of experience and eventually master the driving better than any human could do.
So
when might such system still kill a pedestrian? If you scroll up this
article you’ll notice that there are many possible situations where
wrong assessment of the situation could lead to malfunction, but there
are some cases where the decision might go wrongly more apparently.
Firstly, if the system has not seen enough similar data it might not be able to understand the situation correctly.
Secondly, if the environment is difficult to sense and sensor inputs have low confidence or they send mixed signals.
Thirdly,
if the understanding of sensor input contradicts the understanding
based on system memory (e.g., the object has been considered a lorry
during the previous time steps, but now one sensor thinks it is a dog)
And finally we can not exclude the possibility of malfunction.
I would say that any reasonably designed system is mostly able to handle any of those problems separately, but:
resolving the controversy takes time;
co-occurrence of several contributing factors might lead to wrong decisions and behaviour.
Before looking those situations more closely, let’s briefly cover what modern sensors are capable of and what they are not.
Making sense of sensors
Many
claim that technology is so advanced that Uber car should have
unambiguously identified the pedestrian crossing the road while pushing a
cycle at the wrong place while stepping out from the darkness into the
illuminated area. Which sensors could and could not measure that? And I
mean just measure, not understand what they measure.
Camera can not see in the dark.
Camera is a passive sensor which only works by registering illumination
from the environment. I listed this first, as there are so many
opinions about how good today’s cameras are and how they see in the dark
(e.g., HDR camera).
In fact, they might see under poor lighting conditions, but there must
be some light. There are also infrared or infrared assisted cameras that
will illuminate the environment, but these are superseded by LIDAR and
hence mostly not used on autonomous vehicles. Normal camera will have
hard time to sense something in the darkness behind a bright illuminated
area.
Radar can easily detect moving objects.
It uses radio waves and measures how they reflect back from the object.
Reflected waves from the moving target have noticeable difference in
the wavelength, caused by Doppler shift.
It is difficult to use regular radar for measuring small, slowly moving
or standstill objects as there is only a small difference between waves
reflected back from the still object and waves reflected back from the
ground.
LIDAR works similar to radar, but emits laser light and can easily map any surface in three dimensions.
For wide range 3D imaging most LIDARs are rotating and scanning the
environment a little like a copy machine is scanning a paper. As LIDAR
emits light it does not depend on external illumination and hence can
see in the dark. While expensive LIDARs have incredibly high resolution
this also requires incredibly powerful computer to reconstruct the image in 3D.
So when you see people claiming that LIDAR can work in 10 Hz (meaning
10 3D scans per second) then ask them if they can also process that data
in 10 Hz. While almost every autonomous navigation system on the market
uses LIDAR, Elon Musk thinks LIDAR is only good in short term and Tesla is not using it.
Infrared is a smaller (but older) brother of LIDAR. Thermal infrared can distinguish object by temperature,
and hence is very sensitive to… temperature. So if the sun heats up the
road you might not be able to tell it apart from other objects of the
same temperature. This is why it has limited use in autonomous
navigation.
Ultrasonic sensors are very good for collision avoidance at low speeds.
They are used in most parking sensors on the market, but they have a
small range. So this is why your car’s “city collision avoidance” system
that also uses ultrasonic sensors will not work on the highway — it
would only be able react when it is too late. Collision avoidance
systems that work on the highway are mostly based on radar, like
Tesla’s.
What might go wrong with this system?
For starters, lets take a look at this picture. What do you notice?
“People crossing the crosswalk during busy traffic in the metropolitan urban area with skyscrapers.” by Saketh Garuda on Unsplash
Did
you notice the cyclist? He is obviously not trying to rush between the
cars but will stop and wait until the cars have passed and then crosses
the road:
Snippet from the image above, cyclist annotated.
So the first explanation might be that the algorithm has seen many cyclists waiting on the road for the car to pass.
If an AI would halt for each such cyclist we would consider it a very
poor AI indeed. So can it be that it made a decision not to stop as it
had never seen a cyclist stepping in front of car, but had seen many
waiting the car to pass? This explanation assumes that everything was
working fine, just that there was not enough data to tell the AI that a
cyclist might sometimes step in front of the vehicle. Although Waymo
(then Google car) claimed 2 years ago that they detect cyclists and even their gestures, cyclist detection (and prediction) remains an open research question.
2. Lack of understanding. Take a look at this picture:
Assume
our system is able to tell apart from cyclist that gives way and the
one that does not. The cyclist involved in Uber accident was at the
blind spot. It means that only LIDAR might have been able to detect it
on time to stop the car (i.e., detect before she stepped into
illuminated area). Perhaps it did detect, but cyclist detection from 3D point cloud is much harder task than cyclist detection from an image.
Did it understand it to be cyclist or any kind of object that moves
towards the car trajectory? Perhaps it did not and continued to operate
because objects on the other lane are normal. Similarly, if I was a
pedestrian on this image and did not fully understand what kind of
vehicle has just passed (as on the photo), I could still continue my
journey. Of course, if the vehicle halted it’s trajectory and decided to
drive towards me, I’d be in trouble. But in 99.99% of cases this is not
a reasonable assumption to make.
What happened after illumination?
There are many more reasonable and plausible explanations why the system was not well prepared to avoid the collision. But why didn't it brake when the cyclist was illuminated?
There is no easy answer for this. For certain, deterministic system
would have applied the brakes (though probably not avoid the collision).
If I was testing my car on the street, I’d now probably back it up with
such deterministic systems that run independently from AI. But let’s
take a look at AI.
As I said earlier, all modern
autopilots have memory and they trust their sensors to different extent
depending on the environment. Darkness is a challenging condition
as there is too little illumination to operate camera in real time with
full confidence. Hence it is highly likely, and in 99.99% of cases very
reasonable, that LIDAR input is more trusted at night. As we said
earlier the sensing output of a LIDAR is 10 times per second, but the
processing output really depends on the system, but is probably much
less. You can probably expect 1 scan per second on a decent laptop (this
estimation includes converting raw input to 3D image, locating the
objects from the image and understanding what they are). Using special
hardware will speed up the computation, but probably not up to 10Hz, at
least not on fine-grain resolution.
Let’s
now assume that the AI knows that there is an object in the dark and
trusts LIDAR data more than any other sensor at the time. When the
cyclist steps in front of the car, camera picks it up, perhaps other
sensors too. A deterministic system would hit the brakes as soon as the
signal is interpreted. But for AI this information might look like this:
An Unidentified Flying Object? Or perhaps atmospheric halo?
Lets compare it with autonomous driving AI. (1) On one hand the system
has a trusted sensor, a LIDAR, that tells the car there is nothing in
front of it (because of slow processing it has not seen the movement
yet). (2) Then it probably has a history of sensor measurements where
nothing indicates that any object was going to collide with the car. (3)
And finally, some sensors are telling that there is an obstacle in
front of the car and (4) perhaps algorithms are even able to classify
it. AI now needs to decide.
We must consider that the system is still probabilistic which means that each sensor has some error rate, the measurements are not 100% exact
and each prediction from the sensor data also has an associated error.
What might go wrong? If camera and LIDAR do not agree (or have not yet
been able to match the images) then the system lacks precise 3D data for
camera images and has to reconstruct it only from the images. Lets look
at the disturbing image of the cyclist in Uber accident:
Screenshot from the video that Arizona police released. Annotated.
Without 3D information the system can only rely on machine learning models to detect the object — and as a consequence does not know the distance to the object. How can anything not recognize the cyclist? Here are a few (annoying) thoughts.
The person wears a black jacket which blends with the environment (see
the yellow-dotted area). Many critics will claim that modern cameras
are good enough to separate the jacket from the night. Yes indeed, but
most machine learning algorithms are not able to train a model using
3–20 megapixel images. For real-time operation, the resolution is kept as low as feasible, 1000 x 1000 pixel resolution is probably overestimation, although some authors report being able to process 2M x 1M images,
but still fail to detect a bicycle at night. Mostly, smaller resolution
images are used or pixel values are averaged over some area, forming superpixels. So effectively, there is only a partially visible object.
Without proper 3D information (which provides distance), fragments of the bicycle might be misclassified — see
green and pink annotations on the image. When we (humans) look at the
whole image, we immediately notice the person. When we look at the frame
of the bicycle (annotated with pink dots), it resembles closely the
taillights of a car (also annotated with pink). Returning to the
discussion of probabilities — would the algorithm expect to see taillights or bicycle frame on the road at night in front of the car?
It probably might have seen many taillights of different shape and much
fewer number of bicycles and hence is biased towards classifying the
object as a taillight.
Lastly
I have annotated a spot under the street lamp with orange color. You
can find the equivalent color and shape from the picture.
So
if the error rate of camera was high enough, the autonomous system
might not have trusted it’s input. Perhaps a system might have predicted
a pink area to be a bicycle with 70% confidence and taillights with 77%
confidence? Not an unreasonable result given the circumstances.
I could continue with the listing, but I guess I have made my point: building
an AI that can autonomously drive is a really hard and challenging task
which is prone to errors due to complexity and available training data.
Also, implementing some of this functionality using deterministic algorithms is many orders of magnitude easier.
And it does seem a good idea to equip early self-driving cars with some
deterministic back-up systems to avoid collision. On the other hand, it
is 100% certain, that no-one can build a self-driving car using
deterministic approach.
Finally,
I’ll repeat again that I have no idea what caused the accident, perhaps
it was not related to any of the stuff I described here. But at least
when you see very critical comments in social media which claim that the
technology to prevent the accident existed 1–2–5–10–20 years ago, then
it is possible to acknowledge that this technology has little to do with
fully autonomous driving and it is far from being intelligent. Although
I admit it is hard to accept the fact that a technology exists but the
AI is not yet able to utilize it fully. That said, there is extensive research done on the subject, recent study identified more than 900 hazards that an AI must be able to account for.
So, could AI have saved the cyclist had I programmed the Uber car?
The answer is that no-one knows. The internals of modern AI system are far too complex to assess without having exactly the same data
as was available for the Uber car. In essence, my AI system, or yours,
or Waymo’s, or Tesla’s, would have made a probabilistic decision
too — otherwise it most certainly was not a fully autonomous system. And
perhaps, at least to some extent, making mistakes and learning from
them is inevitable for every intelligent system. That said, we are all
working hard to make autonomous driving safer.
Also, lets back up our AI’s with old school collision avoidance! Intelligence is not the same as perfection, at least for now.
In my previous blog post, I explored some of the early ways of word
embeddings and their shortcomings. The purpose of this post is to
explore one of the most widely used word representations in the natural
language processing industry today.
Word2Vec was created by a team of researchers led by Tomas Mikolov at Google. According to Wikipedia,
Word2vec is a group of related models that are used to produce word embeddings. These models are shallow, two-layer neural networks
that are trained to reconstruct linguistic contexts of words. Word2vec
takes as its input a large corpus of text and produces a vector space, typically of several hundred dimensions, with each unique word in the corpus being assigned a corresponding vector in the space. Word vectors
are positioned in the vector space such that words that share common
contexts in the corpus are located in close proximity to one another in
the space.
There are many resources on the internet providing a detailed
mathematical explanation and derivations of Word2Vec and the reason why
they perform so well. I have included links to some of them at the end
of this post. The purpose of this post is to explore Word2Vec in a
graphical manner in order to get an intuitive feel of how Word2Vec
works, what the vectors mean and why they perform so well.
Let us look at the equation proposed by Mikolov,
As we can see from the equation, it is nothing but a softmax equation.
Intuitively, we can visualize the model as follows. The main operation
being performed here is that of dimensionality reduction. We have seen
the usage of neural networks for dimensionality reduction in auto-encoders.
In auto-encoders, we trick the neural network to learn compressed
representations of vectors by providing the same vector as both input
and target. In this way, the neural network learns to reproduce a vector
from a compressed representation. Hence, we can replace the high
dimension input vectors by their lower dimension hidden activations (Or
weight matrices).
Similarly, in Word2Vec we trick the "neural net" to learn smaller
dimensions representations of the huge dimensioned one hot vector.
But unlike in auto-encoders, we do not provide the same vector as both
target and input vector. Although this can be used to reduce dimensions,
we need to capture the syntactic and semantic meaning of every word. In
order to accomplish that, we need to consider a window of words around
the current word (context). How do we add this context to the
representation of the current word? We make the neural net predict the
current word given its context (CBOW) or to predict the context given
the current word (Skip Gram).
Once the neural net is trained to predict a word given it's context, we
are going to strip off the hidden-output connections (just like
auto-encoders) and use the trained weight matrix between input and
hidden as vector representations (just like auto-encoders)
Graphically, the model can be visualized as follows:
V - Vocabulary Size H - Size of Word2Vec vector
There is a distinct difference between the above model and a normal feed
forward neural network. The hidden layer in Word2Vec are linear neurons
i.e there is no activation function applied on the hidden activations.
Also, we can see that the dimensions of input layer and the output layer
is equal to the vocabulary size. The hidden layer dimension is the size
of the vector which represents a word (which is a tunable
hyper-parameter).
Now, let us take an example in order to understand this better and we'll go through each layer separately.
"The night is darkest just before the dawn rises"
From the above corpus we can see that the vocabulary size is 8.
For simplicity, let us make the following assumptions:
Window size = 1 Word2Vec dimension = 3
The initial one-hot representations will be
The - [1,0,0,0,0,0,0,0] night - [0,1,0,0,0,0,0,0] is - [0,0,1,0,0,0,0,0] darkest - [0,0,0,1,0,0,0,0] just - [0,0,0,0,1,0,0,0] before - [0,0,0,0,0,1,0,0] dawn - [0,0,0,0,0,0,1,0] rises - [0,0,0,0,0,0,0,1]
Let us consider the following scenario, where the current word is darkest and the context word is just. Let us assume that this is a Continuous Bag Of Words (CBOW) model where we predict the current word given the context words.
Input Layer:
Word: just Vector: [0,0,0,0,1,0,0,0]
Hidden Layer:
Dimension = 3 Winput-hidden is of dimension 8X3 Whidden-output is of dimension 3X8
Since the input is a one-hot vector, the hidden activation is just a
lookup operation. That is, hidden activation just looks up the row
corresponding to the word ID in Winput-hidden and passes it on to the output layer. As an illustration,
Output Layer:
Target word - darkest[0,0,0,1,0,0,0,0]
Since the output layer is a softmax layer, it produces a
probability distribution across the words. Thus, the categorical logloss
is calculated (and since this is a softmax, the error is just the
difference between the target vector and the output vector). This error
is then back propagated to the hidden layer.
As you might have noticed, this procedure gives us two trained parameters. The Winput-hidden and Whidden-output. Usually, Whidden-output is discarded.
In the Mikolov's equation we saw above, Vw is the inner representation of the word i.e from Winput-hidden and VIw is the outer representation of the word i.e from Whidden-output.
Inner representation is nothing but the representation of the word when it is the current word and outer representation is when the word occurs in the window of another word.
After the training process, the Winput-hidden is just a lookup table, given the index, it returns the 3 bit inner representation of the word. Similarly, Whidden-output is a lookup table for the outer representation of the word.
Why does this work?
This method accomplishes dual task of reducing the dimensionality and adding semantic meaning to the word. How?
Let us take 2 pairs of words. ('Computers', 'ML') and ('NFL', 'Kobe'). If we look at the above pairs, we can see that 'Computers' and 'ML' occur in the same context in the corpus. Hence, the representations of the words 'Computers' and 'ML' will be very close to each other (cosine similarity). Whereas, there is no way 'NFL' would be a part of a discussion about 'ML'
(Although there is a Kobe challenge on Kaggle, which we are assuming is
absent from the corpus) and hence the similarity between them will be
very low. Since the context will be similar to 'Computer' and 'ML' and 'NFL' and 'Kobe', the neural net is forced to learn similar representations for each of these pairs.
This also handles stemming on a certain level, as 'Computers' and 'Computer' occur in the same context and can be interchanged. This also has the ability to handle acronyms. Since 'ML' and 'Machine' and 'Learning' occur in the same contexts, all 3 words will have similar representations.
One important thing to note is that Word2Vec does not consider the positional variable of the context words i.e whether the word 'Learning' comes before 'Machine' or after is immaterial to the model. It does not learn a different vector for 'Learning' when it occurs before 'Machine' or after.
Here are some of the resources where you can find the detailed mathematical derivation for Word2Vec:
By Risto Miikkulainen
Vice President Research; Professor of Computer Science at the University of Texas at Austin [If you are visiting from Hacker News, please be sure to check out the papers responsible for the development of these apps].
At Sentient, we have an entire team dedicated to research and
experimentation in AI. Over the past few years, the team has focused on
developing new methods in Evolutionary Computation (EC), i.e. designing
artificial neural network architectures, building commercial
applications, and solving challenging computational problems using
methods inspired by natural evolution. This research builds upon more
than 25 years of research at UT Austin and other academic institutions,
and coincides with related efforts recently at OpenAI, DeepMind, Google Brain, and Uber.
There is significant momentum building in this area; indeed, we believe
evolutionary computation may well be the next big thing in AI
technology.
Like Deep Learning (DL), EC was introduced decades ago, and it is
currently experiencing a similar boost from the available big compute
and big data. However, it addresses a distinctly different need: Whereas
DL focuses on modeling what we already know, EC focuses on creating new
knowledge. In that sense, it is the next step up from DL: Whereas DL
makes it possible to recognize new instances of objects and speech
within familiar categories, EC makes it possible to discover entirely
new objects and behaviors—those that maximize a given objective. Thus,
EC makes a host of new applications possible: designing more effective
behaviors for robots and virtual agents; creating more effective and
cheaper health interventions, growth recipes for agriculture, and
mechanical and biological processes.
Today, Sentient released five papers and a web portal
reporting significant progress in taking this step, focusing on three
areas: (1) DL architectures are evolved to exceed state of the art in
three standard machine learning benchmarks; (2) techniques are developed
for increasing performance and reliability of evolution in real-world
applications; and (3) evolutionary problem solving is demonstrated on
very hard computational problems.
This post focuses on the first of these areas, i.e. optimization of DL architectures with EC.
Sentient Reveals Breakthrough Research in Neuroevolution
Much of the power of deep learning comes from the size and complexity
of the networks. With neuroevolution, the DL architecture (i.e. network
topology, modules, and hyperparameters) can be optimized beyond human
ability. The three demos that we will cover in this article are Omni
Draw, Celeb Match, and the Music Maker (Language Modeling). In all three
examples, Sentient successfully surpassed the state-of-the-art DL
benchmark using neuroevolution.
In the Language Modeling domain, the system is trained to predict the
next word in a “language corpus”, i.e. a large collection of text such
as several years of the Wall Street Journal. After the network has made
its prediction, this input can be looped back into its input, and the
network can generate an entire sequence of words. Interestingly, the
same technique applies equally well to musical sequences, where it makes
for a fun demo. The user inputs a few initial notes, and the system
improvises an entire melody based on that starting point. By means of
neuroevolution, Sentient optimized the design of the gated recurrent
(Long Short-Term Memory or LSTM) nodes (i.e. the network’s “memory”
structure) to make the model more accurate in predicting the next note.
In the language modeling domain (i.e. predicting the next word in a language corpus called Penn Tree Bank),
the benchmark is defined by Perplexity Points, a measurement of how
well a probabilistic model can predict real samples. The lower the
number the better, as we want the model to be less “perplexed” when
predicting the next word in a sequence. In this case, Sentient beat the
standard LSTM structure by 10.8 Perplexity Points. Remarkably, although
several human-designed LSTM variations have been proposed, they have not
improved performance much—LSTM structure was essentially unchanged for
25 years. Our neuroevolution experiments
showed that it can, as a matter of fact, be improved significantly by
adding more complexity, i.e. memory cells and more nonlinear, parallel
pathways.
Why does this breakthrough matter? Language is a powerful and complex
construct of human intelligence. Language modeling, i.e. predicting the
next word in a text, is a benchmark that measures how well machine
learning methods can learn language structure. It is therefore a
surrogate for building natural language processing systems that includes
speech and language interfaces, machine translation (such as Google
Translate), and even medical data such as DNA sequences and heart rate
diagnosis. The better we can do in the language modeling benchmark, the
better language processing systems we can build, using the same
technology.
Omniglot is a handwritten character recognition benchmark on
recognizing characters in 50 different alphabets, including real
languages like Cyrillic (written Russian), Japanese, and Hebrew, to
artificial languages such as Tengwar (the written language in Lord of
the Rings).
This demo showcases multitask learning, in which the model learns all
languages at once and exploits the relationship between characters from
different languages. So, for instance, the user inputs an image and the
system outputs suggestions for different character matches in different
languages, saying “this would be ‘X’ in Latin, ‘Y’ in Japanese, and ‘Z’
in Tengwar, etc.”—taking advantage of its understanding of the
relationships between Japanese, Tengwar, and Latin to figure out which
character is the best match. This differs from a single task learning
environment where the model trains on one language at a time and cannot
make the same connections across language data sets.
In this Omniglot multitask character recognition task, our research team improved error of character matching from 32% to 10%.
Omniglot is an example of a dataset that has relatively little data
per language—for instance, it may have only a few characters in Greek
but many in Japanese. It succeeds by using its knowledge of the
relationships between languages to find solutions, hence, finding a
solution in the face of missing or sparse data. Why is this important?
For many real world applications, labeled data is expensive or dangerous
to acquire (e.g., medical applications, agriculture, and robotic
rescue), hence automatically designing models that exploit the
relationships to similar or related datasets could, in a way,
substitute the missing dataset and boost research capabilities. It is
also an excellent demonstration of the power of neuroevolution: there
are many ways in which the languages can be related, and evolution
discovers the best ways to tie their learning together.
The Celeb Match demo deals similarly with multitask learning, but
this time, with a large-scale data sets. The demo is based on the CelebA
dataset, which consists of around 200,000 images of celebrities, each
of which is labeled with 40 binary attributes such as “Male vs. Female”,
“beard vs. no beard”, “glasses vs. no glasses”, etc. Each attribute
induces a “classification task” that induces the system to detect and
identify each attribute. As a fun add-on, we’ve created a demo that
turns this task around: The user can set the desired degree for each
attribute, and the system finds the closest celebrity match, as
determined by the evolved multitask learning network. For instance, if
the current attribute settings result in an image of Brad Pitt, the user
can increase “gray hair” to find which celebrity would be similar to
Brad Pitt but with different hair.
In this domain, the state-of-the-art benchmark is the test error
across all attributes, i.e. whether the system detected the attribute
correctly (male/female, young/mature, large eyes/small eyes), etc. In
the CelebA multitask face classification domain, Sentient used
evolutionary computation to optimize the networks that detect these
attributes, reducing error from 8.00% to 7.94% for an ensemble (an average of) three models.
This technology is a step forward in the ability for AI to predict
diverse attributes of people, places, and things in the physical world.
Unlike networks trained to find similarities based on abstract, learned
features, it makes the similarities semantic and interpretable.
Just the Tip of the Iceberg!
Omni Draw, Celeb Match, and the Music Maker are just three examples of interactive demos that illustrate the power of neuroevolution.
We invite you to learn more about the technology behind them on our
website and papers, as well as the two other aspects of evolution as the
next deep learning: commercialization and solving hard problems.
Read more on our evolution research web portal, Evolution is the New Deep Learning.
We are pleased to announce the open sourcing of
nGraph, a framework-neutral Deep Neural Network (DNN) model compiler
that can target a variety of devices. With nGraph, data scientists can
focus on data science rather than worrying about how to adapt their DNN
models to train and run efficiently on different devices. Continue
reading below for highlights of our engineering challenges and design
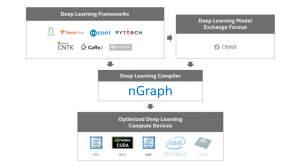
decisions, and see GitHub, our documentation, and our SysML paper for additional details. Figure 1 – nGraph ecosystem. We currently support TensorFlow*,
MXNet*, and neon directly through nGraph. CNTK*, PyTorch*, and Caffe2*
are supported indirectly through ONNX. Users can run these frameworks on
several devices: Intel Architecture, GPU, and Intel Nervana Neural
Network Processor (NNP). Support for future devices/frameworks in our
roadmap is faded.
Why did we build nGraph?
When Deep Learning (DL) frameworks
first emerged as the vehicle for running training and inference models,
they were designed around kernels optimized for a particular device. As a
result, many device details were being exposed in the model
definitions, complicating the adaptability and portability of DL models
to other, or more advanced, devices. The traditional approach means that an
algorithm developer faces tediousness in taking their model to an
upgraded device. Enabling a model to run on a different framework is
also problematic because the developer must separate the essence of the
model from the performance adjustments made for the device, translate to
similar ops in the new framework, and finally make the necessary
changes for the preferred device configuration on the new framework. We designed the nGraph library to
substantially reduce these kinds of engineering complexities. While
optimized kernels for DL primitives are provided through the project and
via libraries like Intel® Math Kernel Library for Deep Neural Networks
(Intel® MKL-DNN), there are also several compiler-inspired ways in which
performance can be further optimized.
How does it work in practice?
Install the nGraph library and write
or compile a framework with the library in order to run training and
inference models. Specify nGraph as the framework backend you want to
use from the command line on any supported system. Our Intermediate
Representation (IR) layer handles all the device abstraction details and
lets developers focus on their data science, algorithms and models,
rather than on machine code. At a more granular level of detail:
The nGraph core creates a strongly-typed and device-neutral stateless graph representation of computations. Each node, or op,
in the graph corresponds to one step in a computation, where each step
produces zero or more tensor outputs from zero or more tensor inputs. Our
philosophy is that nGraph ops should serve as building blocks for more
complex DNN operations found in DL frameworks. This is balanced by the
need for efficient compilation and deriving training computations from
inference computations.
We’ve developed a framework bridge for each supported framework; it acts as an intermediary between the nGraph core
and the framework. We currently have bridges for TensorFlow/XLA, MXNet,
and ONNX. Since ONNX is only an exchange format, the ONNX bridge is
augmented by an execution API.
A
transformer plays a similar role between the nGraph core and the various
devices; transformers handle the device abstraction with a combination
of generic and device-specific graph transformations. The result is a
function that can be executed from the framework bridge. Transformers
also allocate and deallocate, as well as read and write tensors under
direction of the bridge. We currently have transformers for Intel
Architecture, Intel NNP, NVIDIA cuDNN, and additional devices under
active development.
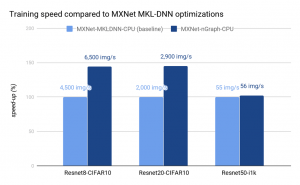
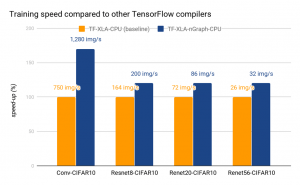
Current Performance
Intel has considerable experience with
MKL-DNN optimization of frameworks for Intel Architecture. We make use
of previous work with the added benefit that optimizations developed for
a device benefits all frameworks through nGraph. Framework developers
continue to perform their own optimization work. For example, the
performance for TensorFlow 1.7+/XLA on Intel Architecture is much better
than for TensorFlow 1.3/XLA on Intel Architectures, and this should improve further as more work is put into XLA for Intel Architectures. We present below initial performance
data from multiple frameworks that reflects the optimizations done so
far on the IA transformer. On the latest Intel Xeon Platinum 8180
processor, in conjunction with MKLDNN v0.13, we are able to meet or
greatly exceed the performance of previously optimized frameworks
such as MXNet-MKLDNN-CPU (MXNet optimized with MKLDNN) and
neon-MKLML-CPU (neon optimized with MKLML). We also deliver better
performance than the TensorFlow XLA compiler (TF-XLA-CPU), but there are
significantly more optimizations that can be done with XLA both on the
default CPU implementation and on nGraph.
Status and Future Work
As of today, nGraph supports six DL frameworks and three compute devices. Supported frameworks:
Direct support through nGraph’s framework-independent representation
TensorFlow*
MXNet*
neon
Indirect support through ONNX
CNTK*
PyTorch*
Caffe2
Supported compute devices:
Intel Architecture (x86, Intel® Xeon® and Xeon Phi®)
We will continue to add support for
additional devices and more graph optimizations such as device-specific
op fusions, better work schedulers and faster custom op kernels. Visit our GitHub repository to learn how to contribute to nGraph.
I was recently chatting to a friend whose startup’s machine learning
models were so disorganized it was causing serious problems as his team
tried to build on each other’s work and share it with clients. Even the
original author sometimes couldn’t train the same model and get similar
results! He was hoping that I had a solution I could recommend, but I
had to admit that I struggle with the same problems in my own work. It’s
hard to explain to people who haven’t worked with machine learning, but
we’re still back in the dark ages when it comes to tracking changes and
rebuilding models from scratch. It’s so bad it sometimes feels like
stepping back in time to when we coded without source control.
When I started out programming professionally in the mid-90’s, the
standard for keeping track and collaborating on source code was Microsoft’s Visual SourceSafe.
To give you a flavor of the experience, it didn’t have atomic
check-ins, so multiple people couldn’t work on the same file, the
network copy required nightly scans to avoid mysterious corruption, and
even that was no guarantee the database would be intact in the morning. I
felt lucky though, one of the places I interviewed at just had a wall
of post-it notes, one for each file in the tree, and coders would take
them down when they were modifying files, and return them when they were
done!
This is all to say, I’m no shrinking violet when it comes to version
control. I’ve toughed my way through some terrible systems, and I can
still monkey together a solution using rsync and chicken wire if I have
to. Even with all that behind me, I can say with my hand on my heart,
that machine learning is by far the worst environment I’ve ever found
for collaborating and keeping track of changes.
To explain why, here’s a typical life cycle of a machine learning model:
A researcher decides to try a new image classification architecture.
She copies and pastes some code from a previous project to handle the input of the dataset she’s using.
This dataset lives in one of her folders on the network. It’s
probably one of the ImageNet downloads, but it isn’t clear which one. At
some point, someone may have removed some of the images that aren’t
actually JPEGs, or made other minor modifications, but there’s no
history of that.
She tries out a lot of slightly different ideas, fixing bugs and
tweaking the algorithms. These changes are happening on her local
machine, and she may just do a mass file copy of the source code to her
GPU cluster when she wants to kick off a full training run.
She executes a lot of different training runs, often changing the
code on her local machine while jobs are in progress, since they take
days or weeks to complete.
There might be a bug towards the end of the run on a large cluster
that means she modifies the code in one file and copies that to all the
machines, before resuming the job.
She may take the partially-trained weights from one run, and use them as the starting point for a new run with different code.
She keeps around the model weights and evaluation scores for all her
runs, and picks which weights to release as the final model once she’s
out of time to run more experiments. These weights can be from any of
the runs, and may have been produced by very different code than what
she currently has on her development machine.
She probably checks in her final code to source control, but in a personal folder.
She publishes her results, with code and the trained weights.
This is an optimistic scenario with a conscientious researcher, but
you can already see how hard it would be for somebody else to come in
and reproduce all of these steps and come out with the same result.
Every one of these bullet points is an opportunity to inconsistencies to
creep in. To make things even more confusing, ML frameworks trade off
exact numeric determinism for performance, so if by a miracle somebody
did manage to copy the steps exactly, there would still be tiny
differences in the end results!
In many real-world cases, the researcher won’t have made notes or
remember exactly what she did, so even she won’t be able to reproduce
the model. Even if she can, the frameworks the model code depend on can
change over time, sometimes radically, so she’d need to also snapshot
the whole system she was using to ensure that things work. I’ve found ML
researchers to be incredibly generous with their time when I’ve
contacted them for help reproducing model results, but it’s often
months-long task even with assistance from the original author.
Why does this all matter? I’ve had several friends contact me about
their struggles reproducing published models as baselines for their own
papers. If they can’t get the same accuracy that the original authors
did, how can they tell if their new approach is an improvement? It’s
also clearly concerning to rely on models in production systems if you
don’t have a way of rebuilding them to cope with changed requirements or
platforms. At that point your model moves from being a high-interest credit card of technical debt
to something more like what a loan-shark offers. It’s also stifling for
research experimentation; since making changes to code or training data
can be hard to roll back it’s a lot more risky to try different
variations, just like coding without source control raises the cost of
experimenting with changes.
It’s not all doom and gloom, there are some notable efforts around
reproducibility happening in the community. One of my favorites is the TensorFlow Benchmarks project Toby Boyd’s
leading. He’s made it his team’s mission not only to lay out exactly
how to train some of the leading models from scratch with high training
speed on a lot of different platforms, but also ensures that the models
train to the expected accuracy. I’ve seen him sweat blood trying to get
models up to that precision, since variations in any of the steps I
listed above can affect the results and there’s no easy way to debug
what the underlying cause is, even with help from the authors. It’s also
a never-ending job, since changes in TensorFlow, in GPU drivers, or
even datasets, can all hurt accuracy in subtle ways. By doing this work,
Toby’s team helps us spot and fix bugs caused by changes in TensorFlow
in the models they cover, and chase down issues caused by external
dependencies, but it’s hard to scale beyond a comparatively small set of
platforms and models.
I also know of other teams who are serious about using models in
production who put similar amounts of time and effort into ensuring
their training can be reproduced, but the problem is that it’s still a
very manual process. There’s no equivalent to source control or even
agreed best-practices about how to archive a training process so that it
can be successfully re-run in the future. I don’t have a solution in
mind either, but to start the discussion here are some principles I
think any approach would need to follow to be successful:
Researchers must be able to easily hack around with new ideas,
without paying a large “process tax”. If this isn’t true, they simply
won’t use it. Ideally, the system will actually boost their
productivity.
If a researcher gets hit by a bus founds their own
startup, somebody else should be able to step in the next day and train
all the models they have created so far, and get the same results.
There should be some way of packaging up just what you need to train
one particular model, in a way that can be shared publicly without
revealing any history the author doesn’t wish to.
To reproduce results, code, training data, and the overall platform need to be recorded accurately.
I’ve been seeing some interesting stirrings in the open source and
startup world around solutions to these challenges, and personally I
can’t wait to spend less of my time dealing with all the related issues,
but I’m not expecting to see a complete fix in the short term. Whatever
we come up with will require a change in the way we all work with
models, in the same way that source control meant a big change in all of
our personal coding processes. It will be as much about getting
consensus on the best practices and educating the community as it will
be about the tools we come up with. I can’t wait to see what emerges!
Researchers have used artificial intelligence (AI) to discover nearly
6,000 previously unknown species of virus. The work, presented on 15
March at a meeting organized by the US Department of Energy (DOE),
illustrates an emerging tool for exploring the enormous, largely unknown
diversity of viruses on Earth.
Although viruses influence
everything from human health to the degradation of trash, they are hard
to study. Scientists cannot grow most viruses in the lab, and attempts
to identify their genetic sequences are often thwarted because their
genomes are tiny and evolve fast.
In recent years, researchers have hunted for unknown viruses by sequencing DNA in samples taken from various environments. To identify the microbes present, researchers search for the genetic signatures of known viruses and bacteria
— just as a word processor’s ‘find’ function highlights words
containing particular letters in a document. But that method often
fails, because virologists cannot search for what they do not know. A
form of AI called machine learning gets around this problem because it can find emergent patterns in mountains of information. Machine-learning algorithms parse data, learn from them and then classify information autonomously.
“Previously,
people had no method to study viruses well,” says Jie Ren, a
computational biologist at the University of Southern California in Los
Angeles. “But now we have tools to find them.”
For the latest
study, Simon Roux, a computational biologist at the DOE Joint Genome
Institute (JGI) in Walnut Creek, California, trained computers to
identify the genetic sequences of viruses from one unusual family,
Inoviridae. These viruses live in bacteria and alter their host’s
behaviour: for instance, they make the bacteria that cause cholera, Vibrio cholerae,
more toxic. But Roux, who presented his work at the meeting in San
Francisco, California, organized by the JGI, estimates that fewer than
100 species had been identified before his research began.
Roux presented a machine-learning algorithm with two sets of data — one containing 805 genomic sequences from known Inoviridae, and
another with about 2,000 sequences from bacteria and other types of
virus — so that the algorithm could find ways of distinguishing between
them.
Next, Roux fed the model massive metagenomic data sets. The
computer recovered more than 10,000 Inoviridae genomes, and clustered
them into groups indicative of different species. The genetic variation
between some of these groups was so wide that Inoviridae is probably
many families, he said. Viral learning
In a separate
study, Deyvid Amgarten, a bioinformatician at the University of São
Paulo in Brazil, deployed machine learning to find viruses in compost
piles at the city’s zoo. He programmed his algorithm to search for a few
distinguishing features of virus genomes, such as the density of genes
in DNA strands of a given length. After the training, the computer
recovered several genomes that seem to be new, says Amgarten, who
presented his results at the JGI meeting. The final step will be to
learn what proteins those viruses produce, and see whether any of them
speed the rate at which organic matter breaks down. “We want to improve
the efficiencies of composting,” he says.
Amgarten took his cue from a machine-learning tool reported last year, called VirFinder1,
from Ren’s team. VirFinder is programmed to notice combinations of DNA
letters, such as AT or CG, in DNA strands. Ren applied the algorithm to
metagenomic samples from faeces of healthy people and those with liver
cirrhosis, a condition caused by diseases ranging from hepatitis to
chronic alcoholism. Once the machine classified groups of viruses in the
samples, the team noticed that particular types were more or less
common in healthy people compared to those with cirrhosis — suggesting
that some viruses might play a part in disease.
Ren’s is a
tantalizing finding: biomedical researchers have long wondered whether
viruses contribute to the symptoms of several elusive conditions, such
as chronic fatigue syndrome (also known as myalgic encephalomyelitis)
and inflammatory bowel disease. Derya Unutmaz, an immunologist at the
Jackson Laboratory for Genomic Medicine in Farmington, Connecticut,
speculates that viruses might trigger a destructive inflammatory
reaction — or they might modify the behaviour of bacteria in a person’s
microbiome, which in turn could destabilize metabolism and the immune
system.
With machine learning, Unutmaz says, researchers might
identify viruses in patients that have remained hidden. Further, because
AI has the ability to find patterns in massive data sets, he says, the
approach might connect data on viruses to bacteria, and then to protein
changes in people with symptoms. Says Unutmaz, “Machine learning could
reveal knowledge we didn’t even think about.”
One
of the main ML problems is text classification, which is used, for
example, to detect spam, define the topic of a news article, or choose
the correct mining of a multi-valued word. The Statsbot team has already written how to train your own model for detecting spam emails, spam messages, and spam user comments. For this article, we asked a data scientist, Roman Trusov, to go deeper with machine learning text analysis.
You
may know it’s impossible to define the best text classifier. In fields
such as computer vision, there’s a strong consensus about a general way
of designing models − deep networks with lots of residual connections.
Unlike that, text classification is still far from convergence on some
narrow area.
In this article, we’ll focus on the few main generalized approaches of text classifier algorithms
and their use cases. Along with the high-level discussion, we offer a
collection of hands-on tutorials and tools that can help with building
your own models.
Text Classification Benchmarks
The
toolbox of a modern machine learning practitioner who focuses on text
mining spans from TF-IDF features and Linear SVMs, to word embeddings
(word2vec) and attention-based neural architectures.
It’s important to distinguish two cases when the effectiveness of a certain method is demonstrated: research and competition.
When
researchers compare the text classification algorithms, they use them
as they are, probably augmented with a few tricks, on well-known
datasets that allow them to compare their results with many other
attempts on the same problem.
The
really remarkable thing about the datasets widely adopted in NLP
research is that both simple and very complex models work on them very
well. To showcase this, let’s discuss two papers:
The
datasets in both cases are the same, and the results in terms of
precision are roughly the same across all the experiments. But the
training and inference time varies greatly between the two.
The
first model takes literally seconds to train, while the second needs
several hours, which would be a game changer when it comes to choosing
the hyperparameters.
What
makes this approach interesting is that their model doesn’t make any
assumptions about the data. At the lowest level they treat the text as a
sequence of characters, allowing the convolutional layers to build the
features in a completely content-agnostic way.
The
second paper features a much lighter model that’s designed to work fast
on a CPU and consists of a joint embedding layer and a softmax
classifier.
On
the other hand, if you take a look at some of the winning solutions on
Kaggle, you’ll see they are dominated by highly customized complex
ensembles.
A good example would be the recent Quora Question Pairs competition and ongoing DeepHack.Turing, where top-ranking solutions consist of several different models: gradient boosting machines, RNNs, and CNNs.
The practical lesson we can learn here
is that despite the results of certain methods published in research,
getting the best performance from the particular tasks in vivo is closer
to art than to science, requiring careful tuning of complicated
pipelines.
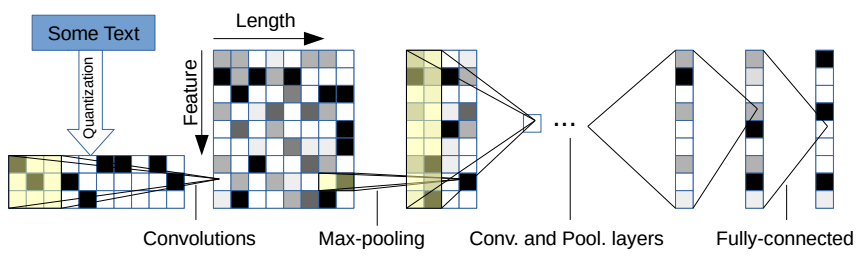
Neural network-based text classifiers typically follow the same linear meta architecture:
Embedding
Deep representation
Fully connected part
Embedding
Embedding
layers take a sequence of word ids as an input and produce a sequence
of corresponding vectors as an output. Their functionality is really
straightforward, and since the actual semantics of those vectors are not
interesting for our problem, the only remaining question is “What is
the best way to initialize the weights?”
Depending
on the problem, the answers may be as counterintuitive as the advice
“generate your own synthetic labels, train word2vec on them, and init
the embedding layer with them.”
But
for all practical purposes you can use a pre-trained set of embeddings
and jointly fine-tune it for your particular model. It’s likely that
resulting word vectors will cease to demonstrate the same properties as
they do in a vanilla word2vec model:
The
go-to solution here is to use pretrained word2vec embeddings and try to
use lower learning rates for the embedding layer (multiply general
learning rate by 0.1).
Deep representation
The main purpose of the deep representation
part is to condense all relevant information in its output while
suppressing the parts that could lead to identifying a single sample
from it. This is highly desirable because the network with high capacity
is likely to overfit on particular examples and perform poorly on the
test set.
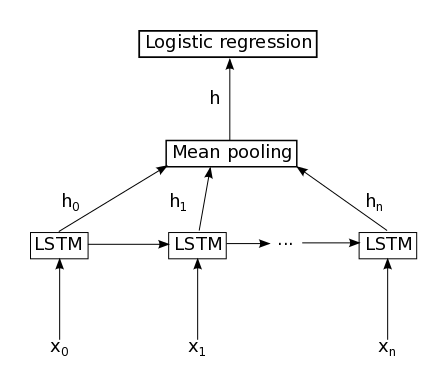
Recurrent neural network (RNN)
When
the problem consists of obtaining a single prediction for a given
document (spam/not spam), the most straightforward and reliable
architecture is a multilayer fully connected text classifier
applied to the hidden state of a recurrent network. Semantics of this
state are considered irrelevant, and the entire vector is treated as a
compressed description of the text.
Since
the main work is being done in the recurrent layer, it’s important to
make sure that it captures only the relevant information. It’s a
frequent challenge for natural language applications and an open
scientific problem.
On a high level, there are two things that can be done here:
Use Bidirectional LSTMs.
This is almost always a good idea, because it essentially captures the
context around each word, instead of sequential “reading.”
Use a transitional layer for embeddings.
LSTMs learn to distinguish important and unimportant parts of the
sequence by themselves, but we can’t be sure that the representation
from the embedding layer is the best input, especially if we don’t
finetune the embeddings. Adding a layer that’s applied to each word
embedding independently can improve your results, acting as a simple
attention layer.
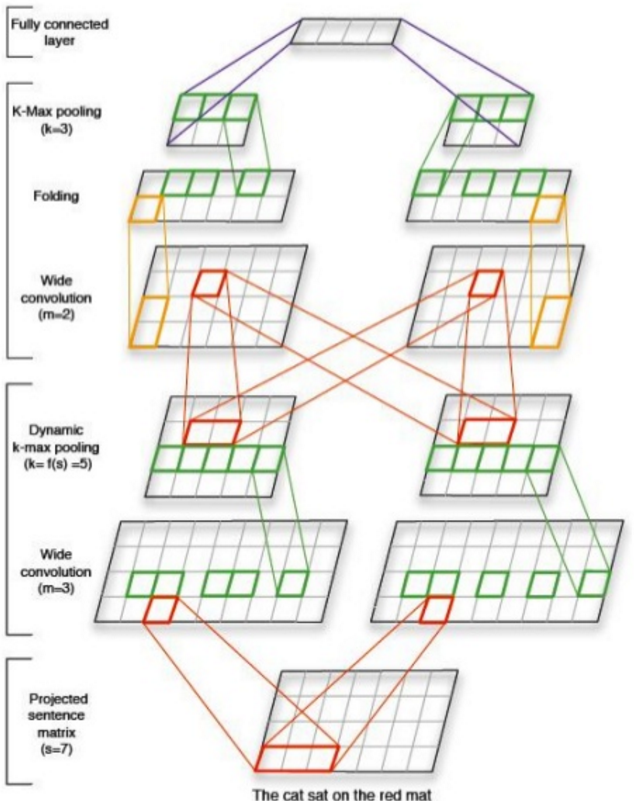
Convolutional neural network (CNN)
An alternative way to train a deep text classifier is to use convolutional networks.
Typically, given a large enough receptive field, you can achieve the
same results as with a dedicated attention layer. There’s no single
trick here, but keeping a lot of feature maps in the beginning and
reducing their number exponentially later helps to avoid learning
irrelevant patterns.
A fully-connected part
performs a series of transformations on the deep representation and
finally outputs the scores for each class. The best practice here is to
apply the transformations as follows:
Fully-connected layer
Batch normalization
(Optional) Non-linear transformation (hyperbolic tangent or ELU)
Dropout
I
hope you like this overview of neural text classifier algorithms that
can be further augmented with more sophisticated methods of your choice.
A few tips and tricks mentioned here are going to help you with
building better models and achieving faster convergence.
In addition, below you’ll find a few links to tutorials and tools for classification and representation learning tasks.