Deep
reinforcement learning has rapidly become one of the hottest research
areas in the deep learning ecosystem. The fascination with reinforcement
learning is related to the fact that, from all the deep learning
modalities, is the one that resemble the most how humans learn. In the
last few years, no company in the world has done more to advance the
stage of deep reinforcement learning than Alphabet’s subsidiary
DeepMind.
Since
the launch of its famous AlphaGo agent, DeepMind has been at the
forefront of reinforcement learning research. A few days ago, they published a new research that attempts to tackle one of the most challenging aspects of reinforcement learning solutions: multi-tasking.
Since
we are infants, multi-tasking becomes an intrinsic element of our
cognition. The ability to performing and learning similar tasks
concurrently is essential to the development of the human mind. From the
neuroscientific standpoint, multi-tasking remains largely a mystery and
that, not surprisingly, we have had a heck of hard time implementing
artificial intelligence(AI) agents that can efficiently learn multiple
domains without requiring a disproportional amount of resources. This
challenge is even more evident in the case of deep reinforcement
learning models that are based on trial and error exercises which can
easily cross the boundaries of a single domain. Biologically speaking,
you can argue that all learning is a multi-tasking exercise.
Let’s
take a classic deep reinforcement learning scenario such as
self-driving vehicles. In that scenarios, AI agents need to concurrently
learn different aspects such as distance, memory or navigation while
operating under rapidly changing parameters such as vision quality or
speed. Most reinforcement learning methods today are focused on learning
a single task and the models that track multi-task learning are too
difficult to scale to be practical.
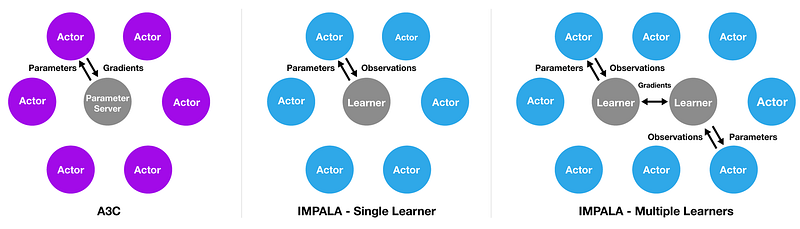
In
their recent research the DeepMind team proposed a new architecture for
deep reinforcement multi-task learning called Importance Weighted
Actor-Learner Architecture (IMPALA). Inspired by another popular
reinforcement learning architecture called A3C,
IMPALA leverages a topology of different actors and learners that can
collaborate to build knowledge across different domains. Traditionally,
deep reinforcement learning models use an architecture based on a single
learner combined with multiple actors. In that model, the Each actor
generates trajectories and sends them via a queue to the learner. Before
starting the next trajectory, actor retrieves the latest policy
parameters from learner. IMPALA uses an architecture that collect
experience which is passed to a central learner that computes gradients,
resulting in a model that has completely independent actors and
learners. This simple architecture enables the learner(s) to be
accelerated using GPUs and actors to be easily distributed across many
machines.
In
addition to the multi-actor architecture model, the IMPALA research
also introduces a new algorithm called V-Trace that focuses off-policy
learning. The idea of V-Trace is to mitigate the lag between when
actions are generated by the actors and when the learner estimates the
gradient.
The DeepMind team tested IMPALA on different scenarios using its famous DMLab-30
training set and the results were impressive. IMPALA proved to achieve
better performance compared to A3C variants in terms of data efficiency,
stability and final performance. This might be the first deep
reinforcement learning models that has been able to efficiently operate
in multi-task environments.
No comments:
Post a Comment