Building a desktop after a decade of MacBook Airs and cloud servers
After
years of using a thin client in the form of increasingly thinner
MacBooks, I had gotten used to it. So when I got into Deep Learning
(DL), I went straight for the brand new at the time Amazon P2 cloud
servers. No upfront cost, the ability to train many models
simultaneously and the general coolness of having a machine learning
model out there slowly teaching itself.
However, as time passed, the AWS bills steadily grew larger, even as I switched to 10x cheaper Spot instances.
Also, I didn’t find myself training more than one model at a time.
Instead, I’d go to lunch/workout/etc. while the model was training, and
come back later with a clear head to check on it.

But
eventually the model complexity grew and took longer to train. I’d
often forget what I did differently on the model that had just completed
its 2-day training. Nudged by the great experiences of the other folks
on the Fast.AI Forum, I decided to settle down and to get a dedicated DL box at home.
The
most important reason was saving time while prototyping models — if
they trained faster, the feedback time would be shorter. Thus it would
be easier for my brain to connect the dots between the assumptions I had
for the model and its results.
Then
I wanted to save money — I was using Amazon Web Services (AWS), which
offered P2 instances with Nvidia K80 GPUs. Lately, the AWS bills were
around $60–70/month with a tendency to get larger. Also, it is expensive
to store large datasets, like ImageNet.
And
lastly, I haven’t had a desktop for over 10 years and wanted to see
what has changed in the meantime (spoiler alert: mostly nothing).
What follows are my choices, inner monologue, and gotchas: from choosing the components to benchmarking.
Table of contents
1. Choosing components
2. Putting it together
3. Software Setup
4. Benchmarks
Choosing the components
A
sensible budget for me would be about 2 years worth of my current
compute spending. At $70/month for AWS, this put it at around $1700 for
the whole thing.
You can check out all the components used. The PC Part Picker site is also really helpful in detecting if some of the components don’t play well together.
GPU
The GPU is the most crucial component in the box. It will train these deep networks fast, shortening the feedback cycle.
The GPU is important is because: a) most calculations in DL are matrix operations, like matrix multiplication. They can be slow if done on the CPU. b) As we are doing thousands of these operations in a typical neural network, the slowness really adds up (as we will see in the benchmarks later). On the other hand, GPUs, rather conveniently, are able to run all these operations in parallel. They have a large number of cores, which can run an even larger number of threads. GPUs also have much higher memory bandwidth which enables them to run these parallel operations on a bunch of data at once.
Disclosure: The following are affiliate links, to help me pay for, well, more GPUs.
The choice is between a few of Nvidia’s cards: GTX 1070, GTX 1070 Ti, GTX 1080, GTX 1080 Ti and finally the Titan X. The prices might fluctuate, especially because some GPUs are great for cryptocurrency mining (wink, 1070, wink).
On performance side: GTX 1080 Ti and Titan X are similar. Roughly speaking the GTX 1080 is about 25% faster than GTX 1070. And GTX 1080 Ti is about 30% faster than GTX 1080. The new GTX 1070 Ti is very close in performance to GTX 1080.
Tim Dettmers has a great article on picking a GPU for Deep Learning, which he regularly updates as new cards come on the market.
Here are the things to consider when picking a GPU:
- Maker: No contest on this one — get Nvidia. They have been focusing on Machine Learning for a number of years now, and it’s paying off. Their CUDA toolkit is entrenched so deeply that it is literally the only choice for the DL practitioner. Note: I wish AMD would pick up their game on this. AMD cards are cheaper and do half-precision compute at full speed.
- Budget: The Titan X got a really bad mark here as it is offering the same performance as the 1080 Ti for about $500-$700 more. It used to be case that you could do same speed half-precision (fp16) on the old, Maxwell-based Titan X, effectively doubling your GPU memory, but not on the new one.
- One or multiple: I considered picking a couple of 1070s (or currently 1070 Ti) instead of 1080 or 1080 Ti. This would have allowed me to either train a model on two cards or train two models at once. Currently training a model on multiple cards is a bit of a hassle, though things are changing with PyTorch and Caffe 2 offering almost linear scaling with the number of GPUs. The other option — training two models at once seemed to have more value, but I decided to get a single more powerful card now and add a second one later.
- Memory: More memory is better. With more memory, we could deploy bigger models and use sufficiently large batch size during training (which helps the gradient flow).
- Memory bandwidth: This enables the GPU to operate on large amounts of memory. Tim Dettmers points out that this is the most important characteristic of a GPU.
Considering all of this, I picked the GTX 1080 Ti, mainly for the training speed boost. I plan to add a second 1080 Ti soonish.
CPU
Even
though the GPU is the MVP in deep learning, the CPU still matters. For
example, data preparation is usually done on the CPU. The number of
cores and threads per core is important if we want to parallelize all
that data prep.
To stay on budget, I picked a mid-range CPU, the Intel i5 7500. It’s relatively cheap but good enough to not slow things down.
Edit: As a few people have pointed out:
“probably the biggest gotcha that is unique to DL/multi-GPU is to pay
attention to the PCIe lanes supported by the CPU/motherboard” (by Andrej Karpathy).
We want to have each GPU have 16 PCIe lanes so it eats data as fast as
possible (16 GB/s for PCIe 3.0). This means that for two cards we need
32 PCIe lanes. However, the CPU I have picked has only 16 lanes. So 2
GPUs would run in 2x8 mode (instead of 2x16). This might be a
bottleneck, leading to less than ideal utilization of the graphics
cards. Thus a CPU with 40 lines is recommended.
Edit 2: However, Tim Dettmers points out that having 8 lanes per card should only decrease performance by “0–10%” for two GPUs. So currently, my recommendation is: Go with 16 PCIe lanes per video card unless it gets too expensive for you. Otherwise, 8 lanes should do as well.
A good solution with to have for a double GPU machine would be an Intel Xeon processor like the E5–1620 v4 (40 PCIe lanes). Or if you want to splurge go for a higher end processor like the desktop i7–6850K.
Memory (RAM)
It’s nice to have a lot of memory if we are to be working with rather big datasets. I got 2 sticks of 16 GB, for a total of 32 GB of RAM, and plan to buy another 32 GB later.
Disk
Following Jeremy Howard’s advice, I got a fast SSD disk to keep my OS and current data on, and then a slow spinning HDD for those huge datasets (like ImageNet).
SSD: I remember when I got my first Macbook Air years ago, how blown away was I by the SSD speed. To my delight, a new generation of SSD called NVMe has made its way to market in the meantime. A 480 GB MyDigitalSSD NVMe drive was a great deal. This baby copies files at gigabytes per second.
HDD: 2 TB Seagate. While SSDs have been getting fast, HDD have been getting cheap. To somebody who has used Macbooks with 128 GB disk for the last 7 years, having this much space feels almost obscene.
SSD: I remember when I got my first Macbook Air years ago, how blown away was I by the SSD speed. To my delight, a new generation of SSD called NVMe has made its way to market in the meantime. A 480 GB MyDigitalSSD NVMe drive was a great deal. This baby copies files at gigabytes per second.
HDD: 2 TB Seagate. While SSDs have been getting fast, HDD have been getting cheap. To somebody who has used Macbooks with 128 GB disk for the last 7 years, having this much space feels almost obscene.
Motherboard
The one thing that I kept in mind when picking a motherboard was the ability to support two GTX 1080 Ti,
both in the number of PCI Express Lanes (the minimum is 2x8) and the
physical size of 2 cards. Also, make sure it’s compatible with the
chosen CPU. An Asus TUF Z270 did it for me.
MSI — X99A SLI PLUS should work great if you got an Intel Xeon CPU.
Power Supply
Rule of thumb: Power supply should provide enough juice for the CPU and the GPUs, plus 100 watts extra.
The Intel i5 7500 processor uses 65W, and the GPUs (1080 Ti) need 250W each, so I got a Deepcool 750W Gold PSU (currently unavailable, EVGA 750 GQ is similar). The “Gold” here refers to the power efficiency, i.e how much of the power consumed is wasted as heat.
The Intel i5 7500 processor uses 65W, and the GPUs (1080 Ti) need 250W each, so I got a Deepcool 750W Gold PSU (currently unavailable, EVGA 750 GQ is similar). The “Gold” here refers to the power efficiency, i.e how much of the power consumed is wasted as heat.
Case
The case should be the same form factor as the motherboard. Also having enough LEDs to embarrass a Burner is a bonus.
A friend recommended the Thermaltake N23 case, which I promptly got. No LEDs sadly.
Budgeting it all in
Here is how much I spent on all the components (your costs may vary):
$700 GTX 1080 Ti
+ $190 CPU
+ $230 RAM
+ $230 SSD
+ $66 HDD
+ $130 Motherboard
+ $75 PSU
+ $50 Case
============
$1671 Total
+ $190 CPU
+ $230 RAM
+ $230 SSD
+ $66 HDD
+ $130 Motherboard
+ $75 PSU
+ $50 Case
============
$1671 Total
Adding tax and fees, this nicely matches my preset budget of $1700.

Putting it all together
If
you don’t have much experience with hardware and fear you might break
something, a professional assembly might be the best option. However,
this was a great learning opportunity that I couldn’t pass (even though
I’ve had my share of hardware-related horror stories).
The first and important step is to read the installation manuals
that came with each component. Especially important for me, as I’ve
done this before once or twice, and I have just the right amount of
inexperience to mess things up.

Install the CPU on the Motherboard

This
is done before installing the motherboard in the case. Next to the
processor there is a lever that needs to be pulled up. The processor is
then placed on the base (double-check the orientation). Finally, the
lever comes down to fix the CPU in place.

.
.
But
I had a quite the difficulty doing this: once the CPU was in position
the lever wouldn’t go down. I actually had a more hardware-capable
friend of mine video walk me through the process. Turns out the amount of force required to get the lever locked down was more than what I was comfortable with.

Next
is fixing the fan on top of the CPU: the fan legs must be fully secured
to the motherboard. Consider where the fan cable will go before
installing. The processor I had came with thermal paste. If yours
doesn’t, make sure to put some paste between the CPU and the cooling
unit. Also, replace the paste if you take off the fan.
Install Power Supply in the Case

I put the Power Supply Unit (PSU) in before the motherboard to get the power cables snugly placed in case back side.
.
.
.
.
Install the Motherboard in the case

Pretty straight forward — carefully place it and screw it in. A magnetic screwdriver was really helpful.
Then connect the power cables and the case buttons and LEDs.
.
.
Install the NVMe Disk

Just slide it in the M2 slot and screw it in. Piece of cake.
.
.
.
.
Install the RAM

The
memory proved quite hard to install, requiring too much effort to
properly lock in. A few times I almost gave up, thinking I must be doing
it wrong. Eventually one of the sticks clicked in and the other one
promptly followed.
At this point, I turned the computer on to make sure it works. To my relief, it started right away!
Install the GPU

Finally, the GPU slid in effortlessly. 14 pins of power later and it was running.
NB: Do not plug your monitor in the external card right away. Most probably it needs drivers to function (see below).
Finally, it’s complete!

Software Setup
Now that we have the hardware in place, only the soft part remains. Out with the screwdriver, in with the keyboard.
Note on dual booting: If
you plan to install Windows (because, you know, for benchmarks, totally
not for gaming), it would be wise to do Windows first and Linux second.
I didn’t and had to reinstall Ubuntu because Windows messed up the boot
partition. Livewire has a detailed article on dual boot.
Install Ubuntu
Most
DL frameworks are designed to work on Linux first, and eventually
support other operating systems. So I went for Ubuntu, my default Linux
distribution. An old 2GB USB drive was laying around and worked great
for the installation. UNetbootin (OSX) or Rufus (Windows) can prepare the Linux thumb drive. The default options worked fine during the Ubuntu install.
At
the time of writing, Ubuntu 17.04 was just released, so I opted for the
previous version (16.04), whose quirks are much better documented
online.
Ubuntu Server or Desktop: The
Server and Desktop editions of Ubuntu are almost identical, with the
notable exception of the visual interface (called X) not being installed
with Server. I installed the Desktop and disabled autostarting X so that the computer would boot it in terminal mode. If needed, one could launch the visual desktop later by typing
startx.Getting up to date
Let’s get our install up to date. From Jeremy Howard’s excellent install-gpu script:
sudo apt-get update sudo apt-get --assume-yes upgrade sudo apt-get --assume-yes install tmux build-essential gcc g++ make binutils sudo apt-get --assume-yes install software-properties-common sudo apt-get --assume-yes install git
The Deep Learning stack
To deep learn on our machine, we need a stack of technologies to use our GPU:
- GPU driver — A way for the operating system to talk to the graphics card.
- CUDA — Allows us to run general purpose code on the GPU.
- CuDNN — Provides deep neural networks routines on top of CUDA.
- A DL framework — Tensorflow, PyTorch, Theano, etc. They make live easier by abstracting the lower levels of the stack.
Install CUDA
Download CUDA from Nvidia, or just run the code below:
wget http://developer.download.nvidia.com/compute/cuda/repos/ubuntu1604/x86_64/cuda-repo-ubuntu1604_8.0.61-1_amd64.deb sudo dpkg -i cuda-repo-ubuntu1604_8.0.61-1_amd64.deb sudo apt-get update sudo apt-get install cuda-toolkit-8.0
Updated to specify version 8 of CUDA. Thanks to Anurag Verma for the tip.
After CUDA has been installed the following code will add the CUDA installation to the PATH variable:
cat >> ~/.bashrc << 'EOF'
export PATH=/usr/local/cuda-8.0/bin${PATH:+:${PATH}}
export LD_LIBRARY_PATH=/usr/local/cuda-8.0/lib64\
${LD_LIBRARY_PATH:+:${LD_LIBRARY_PATH}}
EOF
source ~/.bashrc
Now we can verify that CUDA has been installed successfully by running
nvcc --version # Checks CUDA version nvidia-smi # Info about the detected GPUs
This should have installed the display driver as well. For me,
nvidia-smi showed ERR as the device name, so I installed the latest Nvidia drivers (at the time of writing) to fix it:wget http://us.download.nvidia.com/XFree86/Linux-x86_64/384.98/NVIDIA-Linux-x86_64-384.98.run sudo sh NVIDIA-Linux-x86_64-384.98.run sudo reboot
Removing CUDA/Nvidia drivers
If
at any point the drivers or CUDA seem broken (as they did for
me — multiple times), it might be better to start over by running:
sudo apt-get remove --purge nvidia*
sudo apt-get autoremove
sudo rebootCuDNN
Since version 1.3 Tensorflow supports CuDNN 6, so we install that. To download CuDNN, one needs to register for a (free) developer account. After downloading, install with the following:
tar -xzf cudnn-8.0-linux-x64-v6.0.tgz cd cuda sudo cp lib64/* /usr/local/cuda/lib64/ sudo cp include/* /usr/local/cuda/include/
Anaconda
Anaconda is a great package manager for python. I’ve moved to python 3.6, so will be using the Anaconda 3 version:
wget https://repo.continuum.io/archive/Anaconda3-4.3.1-Linux-x86_64.sh -O “anaconda-install.sh” bash anaconda-install.sh -b cat >> ~/.bashrc << 'EOF' export PATH=$HOME/anaconda3/bin:${PATH} EOF source .bashrc conda upgrade -y --all source activate root
Tensorflow
The popular DL framework by Google. Installation:
sudo apt install python3-pip pip install tensorflow-gpu
Validate Tensorfow install: To make sure we have our stack running smoothly, I like to run the tensorflow MNIST example:
git clone https://github.com/tensorflow/tensorflow.git python tensorflow/tensorflow/examples/tutorials/mnist/fully_connected_feed.py
We should see the loss decreasing during training:
Step 0: loss = 2.32 (0.139 sec) Step 100: loss = 2.19 (0.001 sec) Step 200: loss = 1.87 (0.001 sec)
Keras
Keras is a great high-level neural networks framework, an absolute pleasure to work with. Installation can’t be easier too:
pip install keras
PyTorch
PyTorch
is a newcomer in the world of DL frameworks, but its API is modeled on
the successful Torch, which was written in Lua. PyTorch feels new and
exciting, mostly great, although some things are still to be
implemented. We install it by running:
conda install pytorch torchvision cuda80 -c soumith
Jupyter notebook
Jupyter
is a web-based IDE for Python, which is ideal for data sciency tasks.
It’s installed with Anaconda, so we just configure and test it:
# Create a ~/.jupyter/jupyter_notebook_config.py with settings jupyter notebook --generate-config jupyter notebook --port=8888 --NotebookApp.token='' # Start it
Now if we open
http://localhost:8888 we should see a Jupyter screen.
Run Jupyter on boot
Rather
than running the notebook every time the computer is restarted, we can
set it to autostart on boot. We will use crontab to do this, which we
can edit by running
crontab -e . Then add the following after the last line in the crontab file:# Replace 'path-to-jupyter' with the actual path to the jupyter # installation (run 'which jupyter' if you don't know it). Also # 'path-to-dir' should be the dir where your deep learning notebooks # would reside (I use ~/DL/).
@reboot path-to-jupyter notebook --no-browser --port=8888 --NotebookApp.token='' --notebook-dir path-to-dir &
Outside access
I
use my old trusty Macbook Air for development, so I’d like to be able
to log into the DL box both from my home network, also when on the run.
SSH Key: It’s way more secure to use a SSH key to login instead of a password. Digital Ocean has a great guide on how to setup this.
SSH tunnel: If
you want to access your jupyter notebook from another computer, the
recommended way is to use SSH tunneling (instead of opening the notebook
to the world and protecting with a password). Let’s see how we can do
this:
- First, we need an SSH server. We install it by running the following on the DL box (server):
sudo apt-get install openssh-server sudo service ssh status
2. Then to connect over SSH tunnel, run the following script on the client:
# Replace user@host with your server user and ip. ssh -N -f -L localhost:8888:localhost:8888 user@host
To test this, open a browser and try
http://localhost:8888 from the remote machine. Your Jupyter notebook should appear.
Setup out-of-network access: Finally to access the DL box from the outside world, we need 3 things:
- Static IP for your home network (or a service to emulate that) — so that we know on what address to connect.
- A manual IP or a DHCP reservation giving the DL box a permanent address on your home network.
- Port forwarding from the router to the DL box (instructions for your router).
Setting up out-of-network access depends on the router/network setup, so I’m not going into details.
Benchmarks
Now
that we have everything running smoothly, let’s put it to the test.
We’ll be comparing the newly built box to an AWS P2.xlarge instance,
which is what I’ve used so far for DL. The tests are computer vision
related, meaning convolutional networks with a fully connected model
thrown in. We time training models on: AWS P2 instance GPU (K80), AWS P2
virtual CPU, the GTX 1080 Ti and Intel i5 7500 CPU.
MNIST Multilayer Perceptron
The “Hello World” of computer vision. The MNIST database consists of 70,000 handwritten digits. We run the Keras example on MNIST
which uses Multilayer Perceptron (MLP). The MLP means that we are using
only fully connected layers, not convolutions. The model is trained for
20 epochs on this dataset, which achieves over 98% accuracy out of the
box.
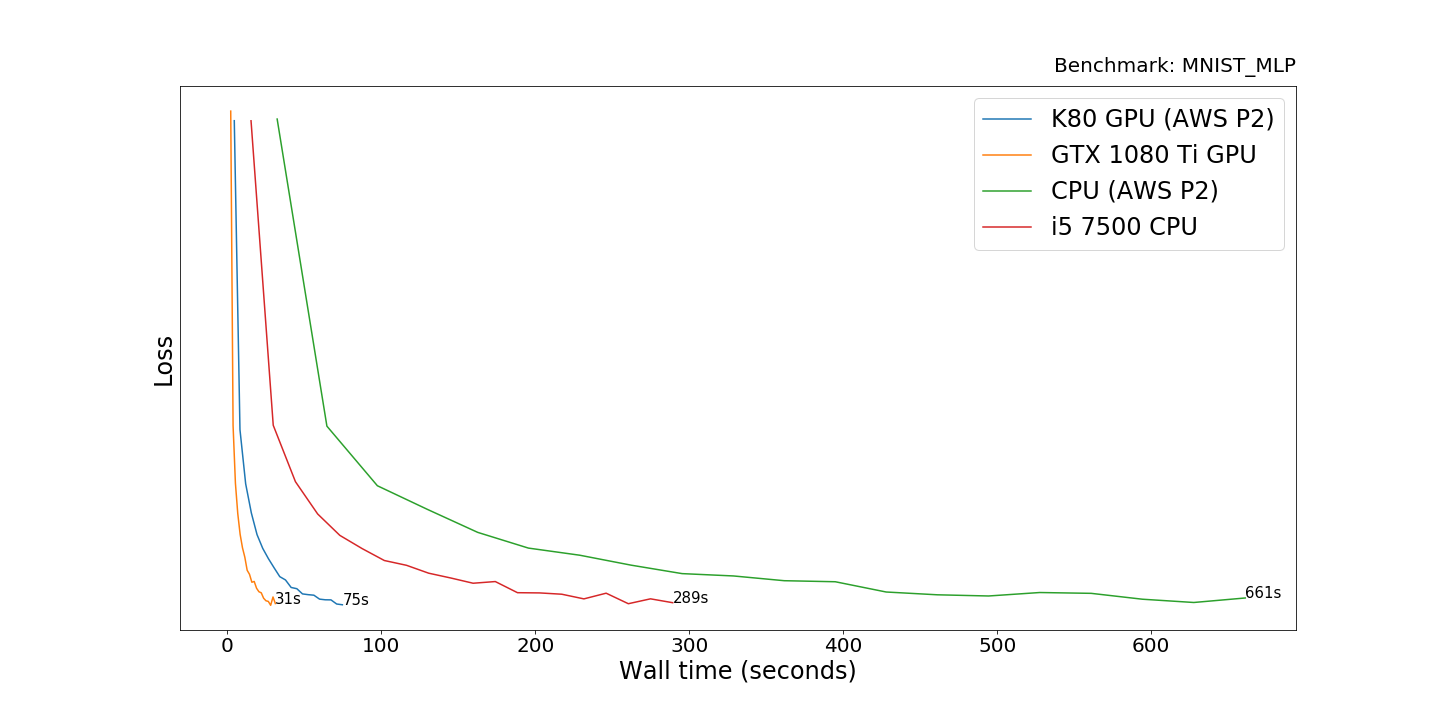
We see that the GTX 1080 Ti is 2.4 times faster than the K80 on AWS P2 in training the model. This is rather surprising as these 2 cards should have about the same performance. I believe this is because of the virtualization or underclocking of the K80 on AWS.
The
CPUs perform 9 times slower than the GPUs. As we will see later, it’s a
really good result for the processors. This is due to the small model
which fails to fully utilize the parallel processing power of the GPUs.
Interestingly, the desktop Intel i5–7500 achieves 2.3x speedup over the virtual CPU on Amazon.
VGG Finetuning
A VGG net will be finetuned for the Kaggle Dogs vs Cats competition.
In this competition, we need to tell apart pictures of dogs and cats.
Running the model on CPUs for the same number of batches wasn’t
feasible. Therefore we finetune for 390 batches (1 epoch) on the GPUs
and 10 batches on the CPUs. The code used is on github.
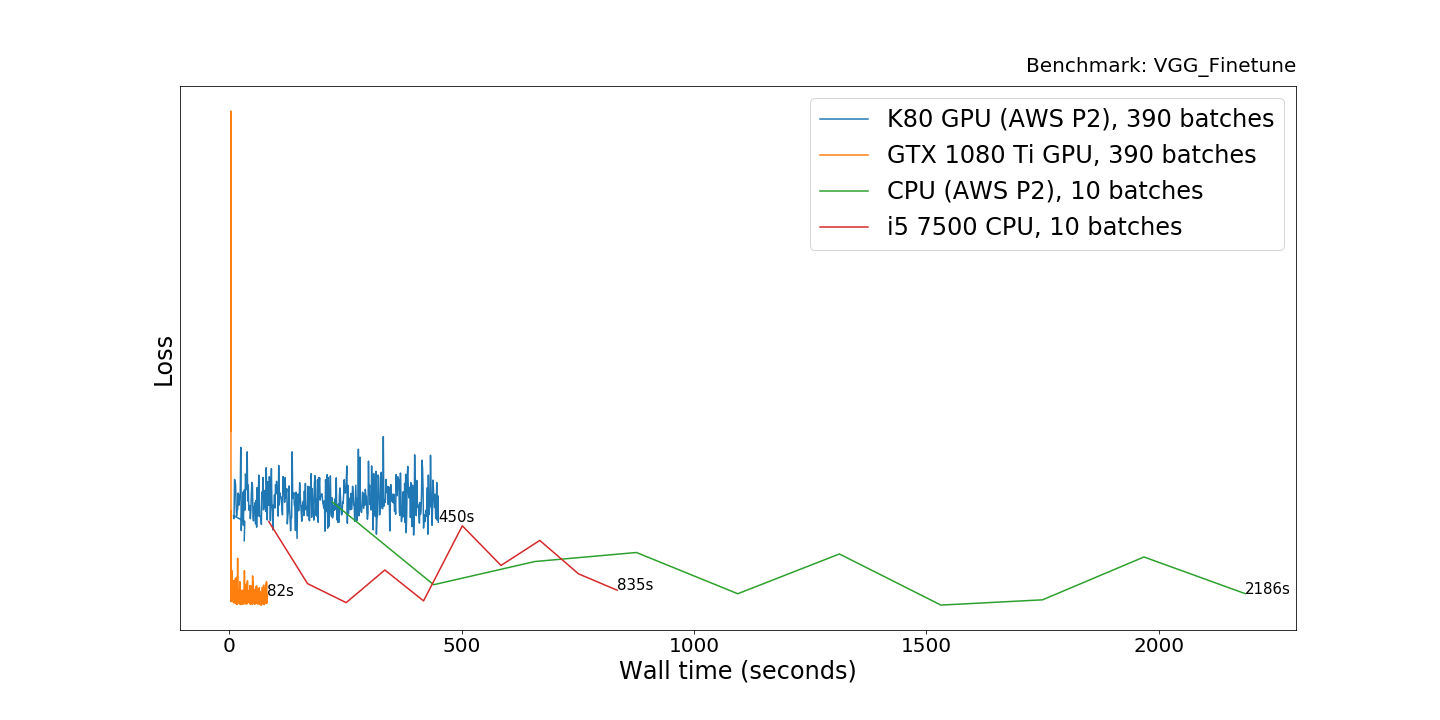
The 1080 Ti is 5.5 times faster that the AWS GPU (K80). The
difference in the CPUs performance is about the same as the previous
experiment (i5 is 2.6x faster). However, it’s absolutely impractical to
use CPUs for this task, as the CPUs were taking ~200x more time on this
large model that includes 16 convolutional layers and a couple semi-wide
(4096) fully connected layers on top.
Wasserstein GAN
A
GAN (Generative adversarial network) is a way to train a model to
generate images. GAN achieves this by pitting two networks against each
other: A Generator which learns to create better and better images, and a
Discriminator that tries to tell which images are real and which are
dreamt up by the Generator.
The Wasserstein GAN is an improvement over the original GAN. We will use a PyTorch implementation, that is very similar to the one by the WGAN author.
The models are trained for 50 steps, and the loss is all over the place
which is often the case with GANs. CPUs aren’t considered.
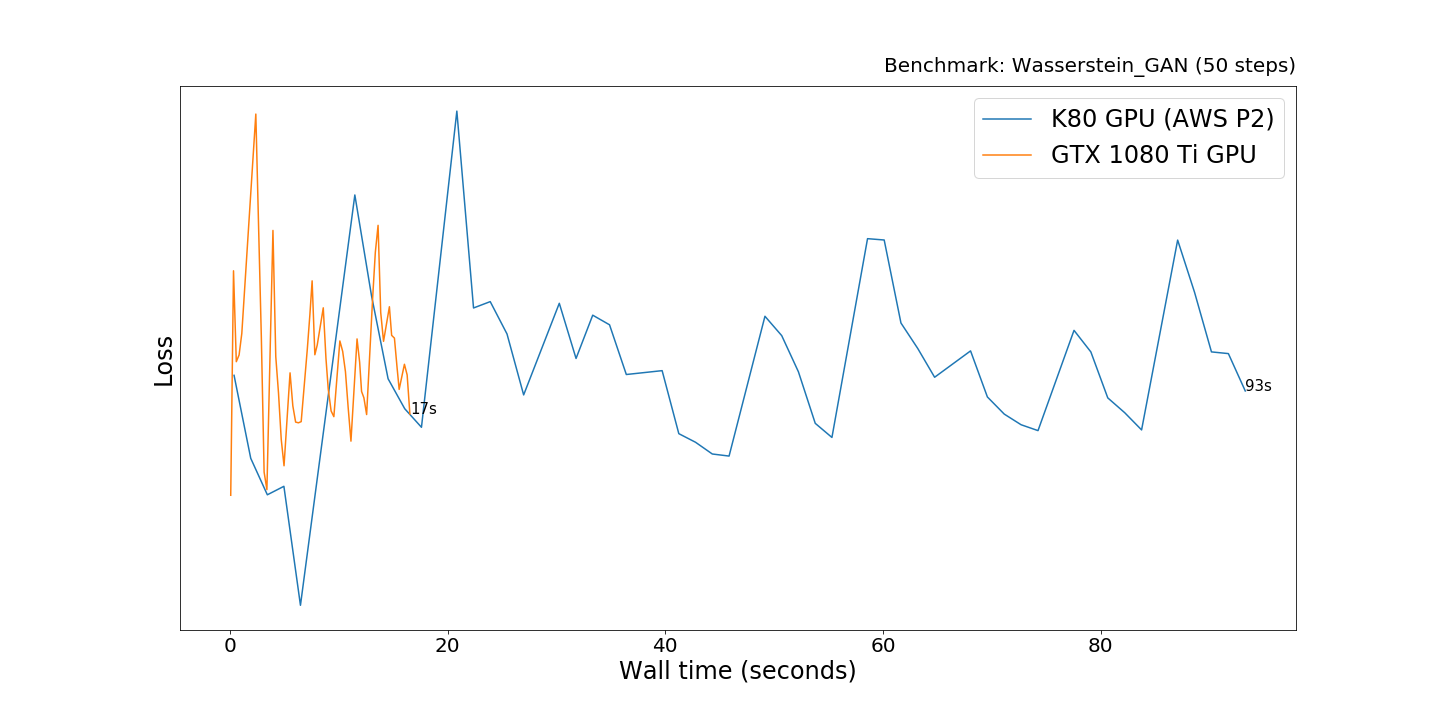
The GTX 1080 Ti finishes 5.5x faster than the AWS P2 K80, which is in line with the previous results.
Style Transfer
The final benchmark is on the original Style Transfer paper (Gatys et al.), implemented on Tensorflow (code available).
Style Transfer is a technique that combines the style of one image (a
painting for example) and the content of another image. Check out my previous post for more details on how Style Transfer works.
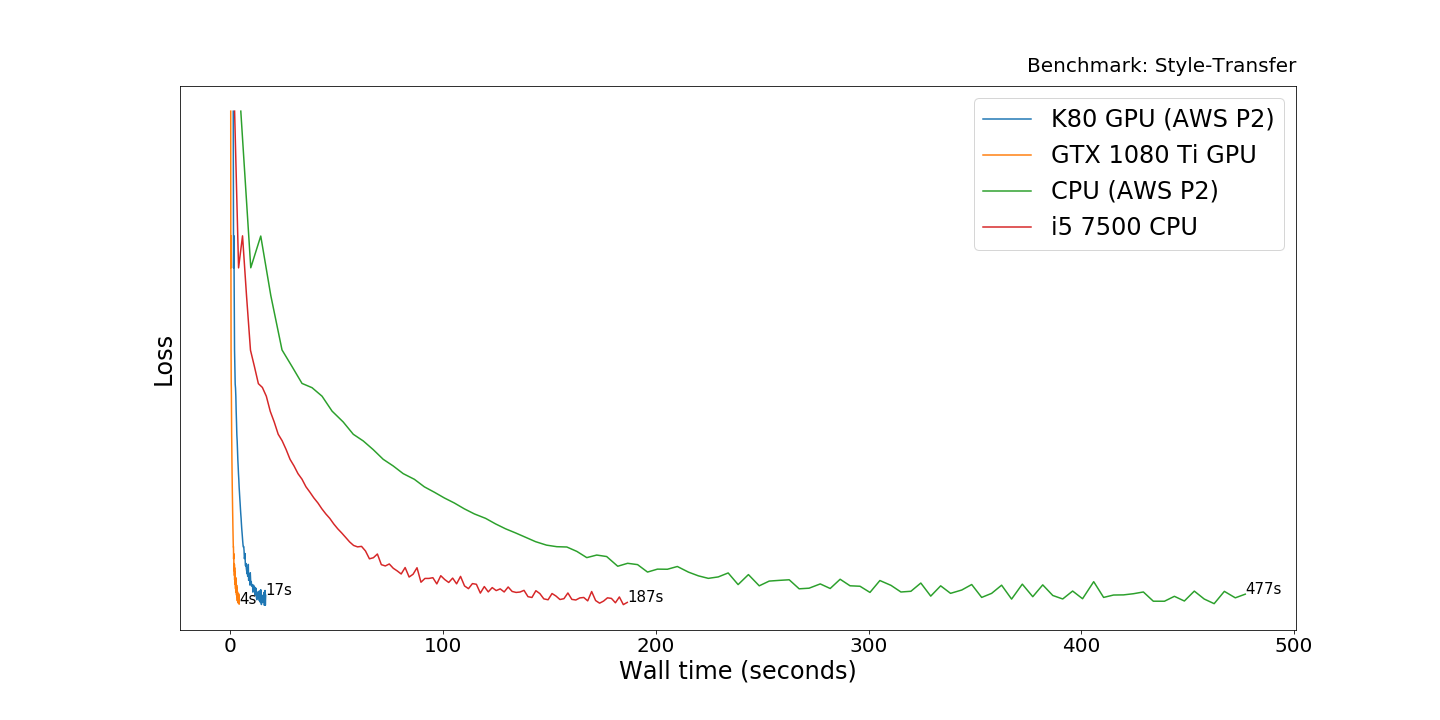
The GTX 1080 Ti
outperforms the AWS K80 by a factor of 4.3. This time the CPUs are
30-50 times slower than graphics cards. The slowdown is less than on the
VGG Finetuning task but more than on the MNIST Perceptron experiment.
The model uses mostly the earlier layers of the VGG network, and I
suspect this was too shallow to fully utilize the GPUs.
The
DL box is in the next room and a large model is training on it. Was it a
wise investment? Time will tell but it is beautiful to watch the
glowing LEDs in the dark and to hear its quiet hum as models are trying
to squeeze out that extra accuracy percentage point.
No comments:
Post a Comment