Capsule networks (CapsNets) are a hot new neural net architecture
that may well have a profound impact on deep learning, in particular for
computer vision. Wait, isn't computer vision pretty much solved
already? Haven't we all seen fabulous examples of convolutional neural
networks (CNNs) reaching super-human level in various computer vision
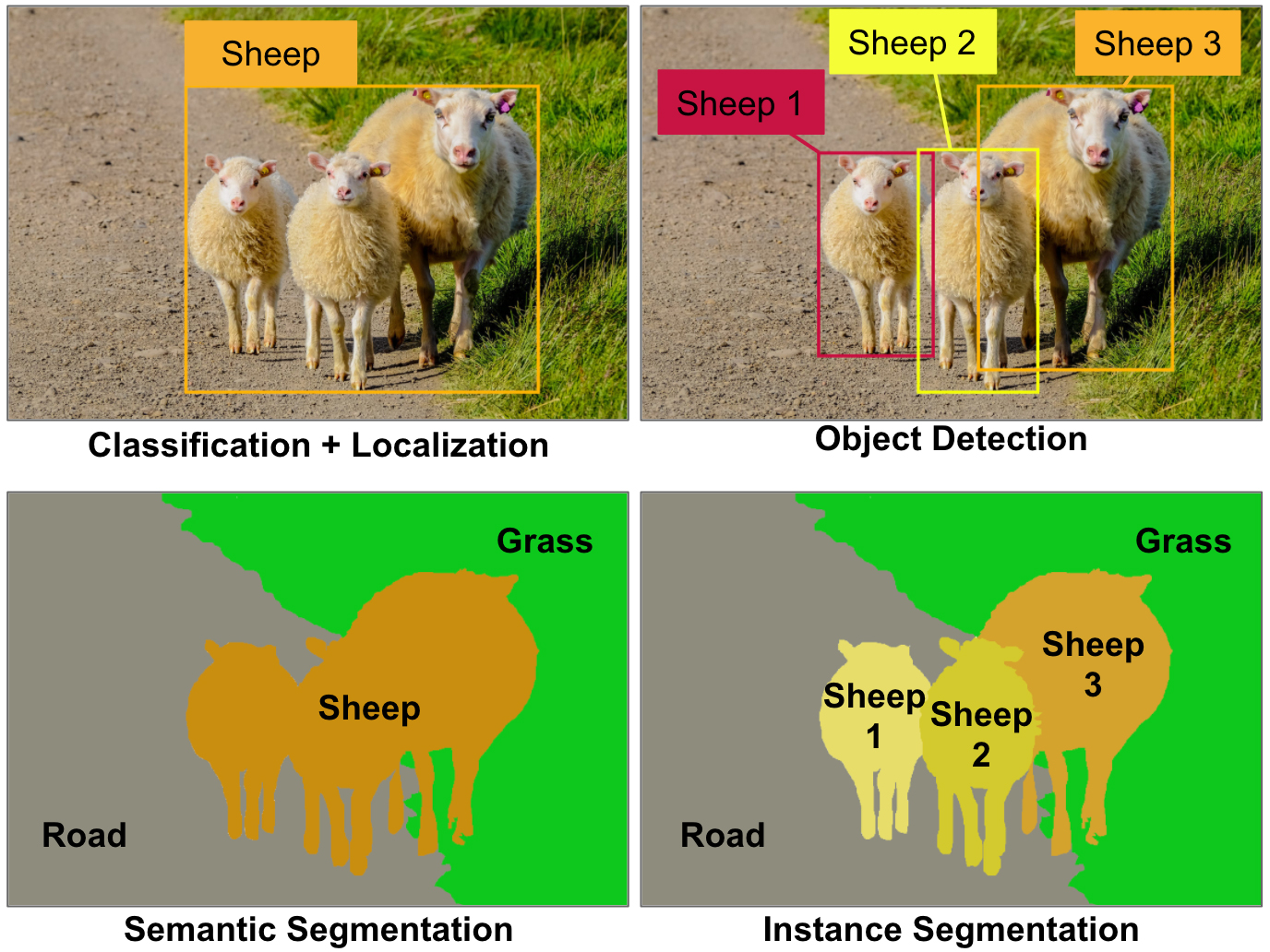
tasks, such as classification, localization, object detection, semantic
segmentation or instance segmentation (see Figure 1)? Figure 1. Some
of the main computer vision tasks. Today, each of these tasks requires a
very different CNN architecture, for example ResNet for classification,
YOLO for object detection, Mask R-CNN for instance segmentation, and so
on. Image by Aurélien Géron.
Well, yes, we’ve seen fabulous CNNs, but:
They were trained on huge numbers of images (or they reused parts
of neural nets that had). CapsNets can generalize well using much less
training data.
CNNs don’t handle ambiguity very well. CapsNets do, so they can
perform well even on crowded scenes (although, they still struggle with
backgrounds right now).
CNNs lose plenty of information in the pooling layers. These layers
reduce the spatial resolution (see Figure 2), so their outputs are
invariant to small changes in the inputs. This is a problem when
detailed information must be preserved throughout the network, such as
in semantic segmentation. Today, this issue is addressed by building
complex architectures around CNNs to recover some of the lost
information. With CapsNets, detailed pose information (such as precise
object position, rotation, thickness, skew, size, and so on) is
preserved throughout the network, rather than lost and later recovered.
Small changes to the inputs result in small changes to the
outputs—information is preserved. This is called "equivariance." As a
result, CapsNets can use the same simple and consistent architecture
across different vision tasks.
Finally, CNNs require extra components to automatically identify
which object a part belongs to (e.g., this leg belongs to this sheep).
CapsNets give you the hierarchy of parts for free.
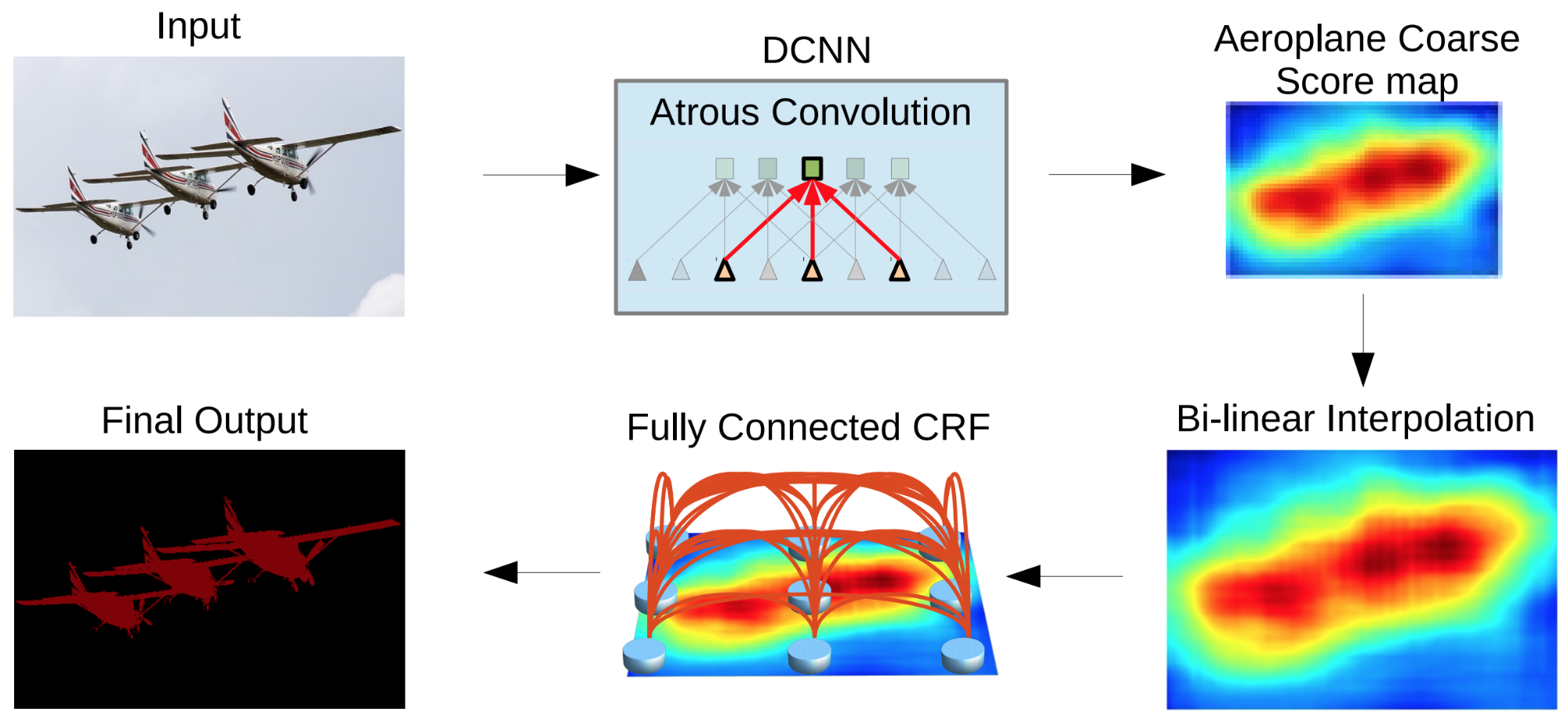
Figure 2. The
DeepLab2 pipeline for image segmentation, by Liang-Chieh Chen, et al.:
notice that the output of the CNN (top right) is very coarse, making it
necessary to add extra steps to recover some of the lost details. From
the paperDeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs, figure reproduced with the kind permission of the authors. See this great post by S. Chilamkurthy to see how diverse and complex the architectures for semantic segmentation can get.
CapsNets were first introduced in 2011 by Geoffrey Hinton, et al., in a paper called Transforming Autoencoders,
but it was only a few months ago, in November 2017, that Sara Sabour,
Nicholas Frosst, and Geoffrey Hinton published a paper called Dynamic Routing between Capsules,
where they introduced a CapsNet architecture that reached
state-of-the-art performance on MNIST (the famous data set of
handwritten digit images), and got considerably better results than CNNs
on MultiMNIST (a variant with overlapping pairs of different digits).
See Figure 3. Figure 3. MultiMNIST
images (white) and their reconstructions by a CapsNet (red+green). “R” =
reconstructions; “L” = labels. For example, the predictions for the
first example (top left) are correct, and so are the reconstructions.
But in the fifth example, the prediction is wrong: (5,7) instead of
(5,0). Therefore, the 5 is correctly reconstructed, but not the 0. From
the paper: Dynamic routing between capsules, figure reproduced with the kind permission of the authors.
Despite all their qualities, CapsNets are still far from perfect.
Firstly, for now they don't perform as well as CNNs on larger images
such as CIFAR10 or ImageNet. Moreover, they are computationally
intensive, and they cannot detect two objects of the same type when they
are too close to each other (this is called the "crowding problem," and
it has been shown that humans have it, too).
But the key ideas are extremely promising, and it seems likely that
they just need a few tweaks to reach their full potential. After all,
modern CNNs were invented in 1998, yet they only beat the state of the
art on ImageNet in 2012, after a few tweaks.
Get O'Reilly's AI newsletter
So, what are CapsNets exactly?
In short, a CapsNet is composed of capsules rather than neurons. A
capsule is a small group of neurons that learns to detect a particular
object (e.g., a rectangle) within a given region of the image, and it
outputs a vector (e.g., an 8-dimensional vector) whose length represents
the estimated probability that the object is present[1],
and whose orientation (e.g., in 8D space) encodes the object's pose
parameters (e.g., precise position, rotation, etc.). If the object is
changed slightly (e.g., shifted, rotated, resized, etc.) then the
capsule will output a vector of the same length, but oriented slightly
differently. Thus, capsules are equivariant.
Much like a regular neural network, a CapsNet is organized in
multiple layers (see Figure 4). The capsules in the lowest layer are
called primary capsules: each of them receives a small region of the
image as input (called its receptive field), and it tries to detect the
presence and pose of a particular pattern, for example a rectangle.
Capsules in higher layers, called routing capsules, detect larger and
more complex objects, such as boats. Figure 4. A
two-layer CapsNet. In this example, the primary capsule layer has two
maps of 5x5 capsules, while the second capsule layer has two maps of 3x3
capsules. Each capsule outputs a vector. Each arrow represents the
output of a different capsule. Blue arrows represent the output of a
capsule that tries to detect triangles, black arrows represent the
output of a capsule that tries to detect rectangles, and so on. Image by
Aurélien Géron.
The primary capsule layer is implemented using a few regular
convolutional layers. For example, in the paper, they use two
convolutional layers that output 256 6x6 features maps containing
scalars. They reshape this output to get 32 6x6 maps containing
8-dimensional vectors. Finally, they use a novel squashing function to
ensure these vectors have a length between 0 and 1 (to represent a
probability). And that's it: this gives the output of the primary
capsules.
The capsules in the next layers also try to detect objects and their
pose, but they work very differently, using an algorithm called routing
by agreement. This is where most of the magic of CapsNets lies. Let's
look at an example.
Suppose there are just two primary capsules: one rectangle capsule
and one triangle capsule, and suppose they both detected what they were
looking for. Both the rectangle and the triangle could be part of either
a house or a boat (see Figure 5). Given the pose of the rectangle,
which is slightly rotated to the right, the house and the boat would
have to be slightly rotated to the right as well. Given the pose of the
triangle, the house would have to be almost upside down, whereas the
boat would be slightly rotated to the right. Note that both the shapes
and the whole/part relationships are learned during training. Now notice
that the rectangle and the triangle agree on the pose of the boat,
while they strongly disagree on the pose of the house. So, it is very
likely that the rectangle and triangle are part of the same boat, and
there is no house. Figure 5. Routing
by agreement, step 1—predict the presence and pose of objects based on
the presence and pose of object parts, then look for agreement between
the predictions. Image by Aurélien Géron.
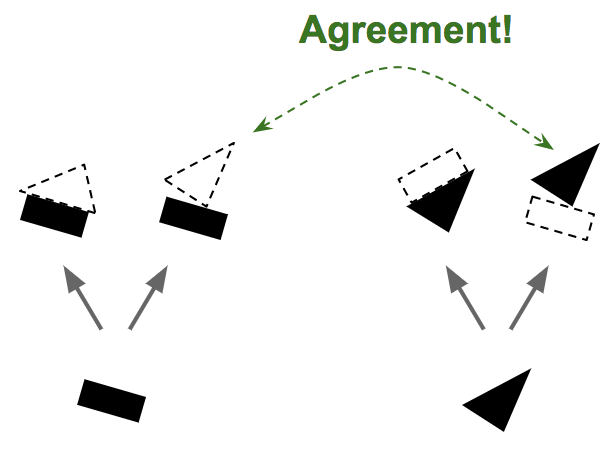
Since we are now confident that the rectangle and triangle are part
of the boat, it makes sense to send the outputs of the rectangle and
triangle capsules more to the boat capsule, and less to the house
capsule: this way, the boat capsule will receive more useful input
signal, and the house capsule will receive less noise. For each
connection, the routing-by-agreement algorithm maintains a routing
weight (see Figure 6): it increases routing weight when there is
agreement, and decreases it in case of disagreement.
Figure 6. Routing by agreement, step 2—update the routing weights. Image by Aurélien Géron.
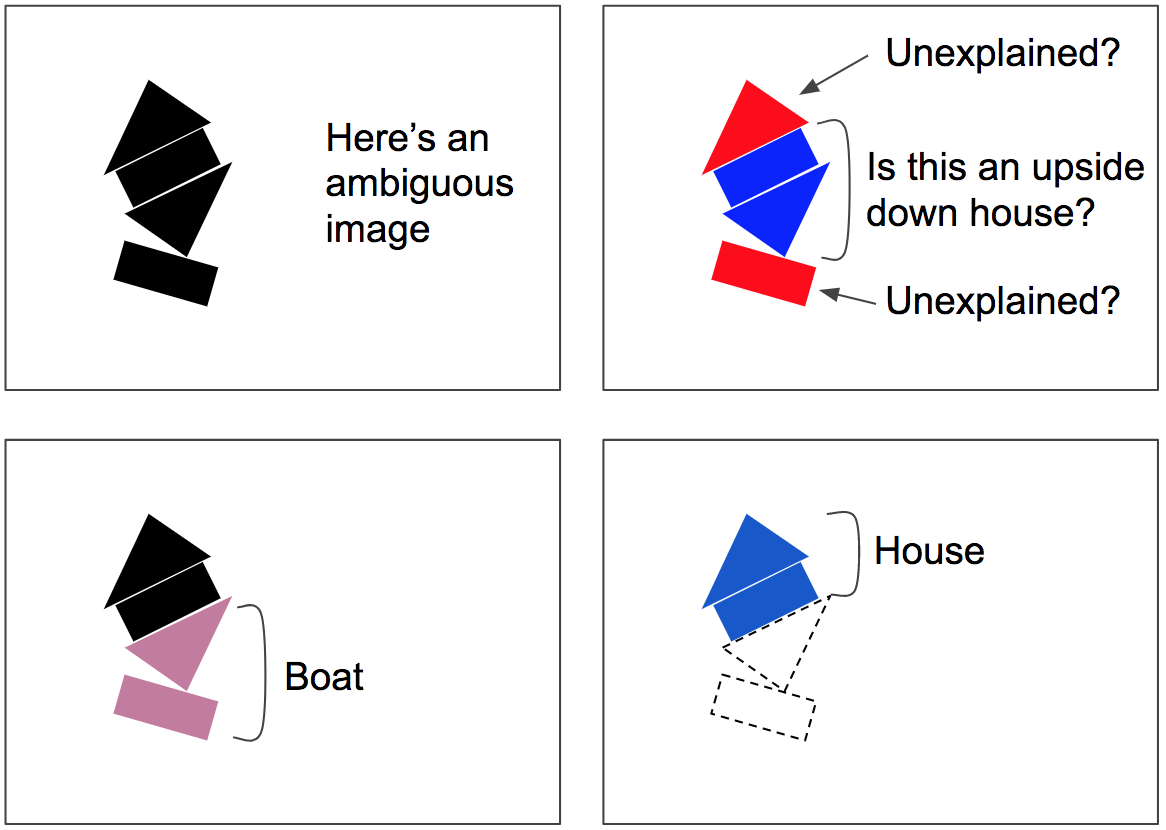
The routing-by-agreement algorithm involves a few iterations of
agreement-detection + routing-update (note that this happens for each
prediction, not just once, and not just at training time). This is
especially useful in crowded scenes: for example, in Figure 7, the scene
is ambiguous because you could see an upside-down house in the middle,
but this would leave the bottom rectangle and top triangle unexplained,
so the routing-by-agreement algorithm will most likely converge to a
better explanation: a boat at the bottom, and a house at the top. The
ambiguity is said to be "explained away": the lower rectangle is best
explained by the presence of a boat, which also explains the lower
triangle, and once these two parts are explained away, the remaining
parts are easily explained as a house. Figure 7. Routing
by agreement can parse crowded scenes, such as this ambiguous image,
which could be misinterpreted as an upside-down house plus some
unexplained parts. Instead, the lower rectangle will be routed to the
boat, and this will also pull the lower triangle into the boat as well.
Once that boat is “explained away,” it’s easy to interpret the top part
as a house. Image by Aurélien Géron.
And that’s it—you know the key ideas behind CapsNets! If you want more details, check out my two videos on CapsNets (one on the architecture and another on the implementation) and my commented TensorFlow implementation (Jupyter Notebook). Please don’t hesitate to comment on the videos, file issues on GitHub if you see any, or contact me on Twitter @aureliengeron. I hope you found this post useful!






No comments:
Post a Comment