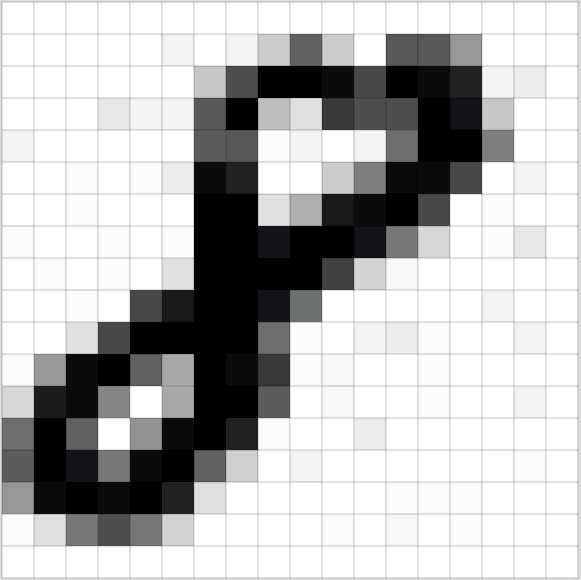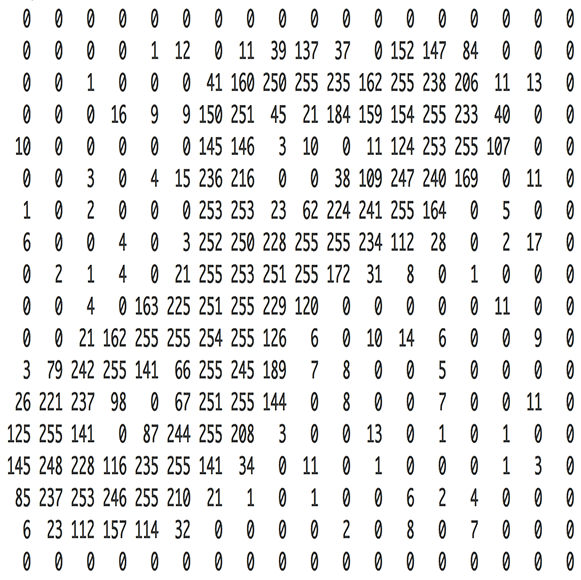microRTS is a very simple Java implementation of an RTS game designed
to test AI techniques. The motivation to create microRTS was to be able
to test simple AI techniques without having to invest the high
development time that is required to start working with Wargus or
Starcraft using BWAPI. Also, for some AI techniques, one needs to know
the exact details of the transition function used in the game, which is
not available for some of those games.
microRTS is deterministic, fully-observable and real-time (i.e.
players can issue actions simultaneously, and actions are durative). For
that reason, it is not adequate for evaluating techniques designed to
address non-determinism or partial observability. I created it for
testing, in particular, game-tree search techniques such as Monte Carlo
search algorithms.
Although microRTS is designed to run without the need for a
visualization (since it is not meant to be for a human to play, but for
AIs), it comes with a simple visualization panel that can be used to see
games in real-time. Here's a screenshot of a game in progress:
The image shows some of the features of microRTS (more details in the
GameDefinition page): the game map is a grid (that can have walls), all
the units are 1x1 tiles big. The green boxes are resources, the
white/grey squares are buildings, and the circles are moving units. The
screenshot shows a scripted LightRush AI (that implements a quick melee
unit rush) against a random AI, that just executes actions at random (as
can be seen, since it simply trained a collection of workers and moved
them to random places).
Maps can be defined directly in code, or using xml files.
We
are living in an era of hype. In this article, I am trying to discover
the hype around Artificial Intelligence. The First thing I want to clear
is that ML/DL are algorithms, neither conscious nor intelligent or
smart machines.
There’s more to Artificial General Intelligence
than just Machine Learning or Deep Learning. I agree that Deep Learning
has penetrated industries and it holds the potential to disrupt
industries, but it is nowhere near to being conscious or an intelligent
machines.
The term Masses is so powerful that once aligned together, it brings revolutions.
Singularity, AI taking over the world, End of the world
were one of the most used phrases in the media last year. Media being a
primary source of information for most of the people, including
investors and financial institutions which makes it a vicious circle
fuelling the hype and adding air to the bubble. It can be good or bad,
but if it bursts it is going to affect us all (includes you too). If you talk to the researchers or the experts, their views on this are poles apart. They echo AI is over-hyped and AGI is far away.
We have a long way to go to achieve true Intelligence. Current AI(Deep
learning/Machine Learning) applications can only do what they are
trained to do. When the knowledge flows from the source to the
publications, it gets distorted.
AI is a pie and everyone wants to have a bite of it.
AI/ML
tools are limited to the researchers, industry, colleges and labs. They
are not accessible to the masses in a simple easy-to-use form. In the
last 2–3 years we have seen some pretty interesting use cases of modern
deep learning. Apps likes Prisma showed us that we just need to be
creative to make it available to the masses. It uses deep learning to
extract styles from images(“Vincent Van Gogh’s Starry night”, “Picasso’s
Self Portrait 1907”, “Frida Cahlo”) and apply extracted styles on to
your images. AI as a lawyer, AI as a painter and AI as a doctor and so
on, just name it and you will find a startup/company working on it.
If
I talk about industry use cases, Baidu runs a food delivery service and
it uses AI to predict how long the food will take to get to the
customers. Google uses deep learning for machine translation, search and
for other products. Facebook uses it to recognize faces in your images
which you upload on Facebook. GANs (Generative Adversarial Network) are
the type of neural networks which learns to imitate and produce original
content. Google Research used GANs to invent an “encryption” protocol.
Andrew Ng, Chief Scientist at Baidu research says
AI is the new electricity
In
the next 3–5 years AI/ML is going to affect almost every industry.
Infact it is a new industry and it is worth billions of dollars right
now. A report by Bank of America Merrill Lynch forecasts it to be USD 14
Trillion by 2025, and it is a HUGE number.
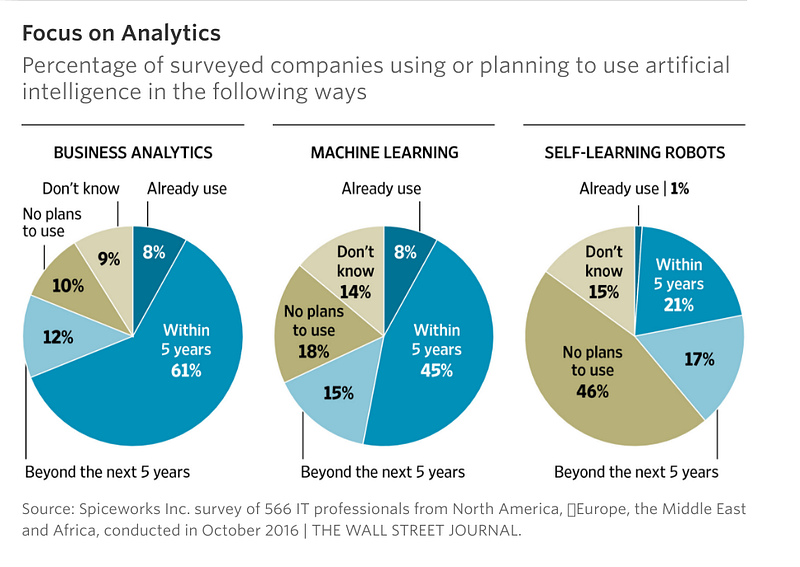
Source: Wall Street Journal
61%
of companies in this survey by Wall Street Journal are planning to use
AI within 5 years for business analytics, 45% for Machine Learning and
21% for self-learning robots. According Stackoverflow’s Report,
the global economy is seeing an explosion in the demand for Machine
Learning expertise this year as much as 3700 times more than year 2016. This is HUGE!
And, we
are missing out on one very important user group, which is general
people. What if users can participate in the creation of the AGI.
Creative users, coming out with use cases which we had never thought of.
What they need is easy-to-use tools. AI with
everyone is the future of AI. Personal computers revolutionised
industries and powered people with tools that amplify one’s creativity
and productivity. Internet came out and connected us all together.
Handheld devices like Mobile and tablets have given us all of that power
in our hands. Now it’s time for AI to go into everyone’s hands, next
revolution is getting in shape now and everyone has to participate in
shaping it. AI can find the cure for diseases which we were unable to
cure for centuries like Cancer, Sclerosis and other diseases. It holds
the power for a better future, a future which we have always dreamt of.
As
far as the world is progressing, most of the programming might not even
exist in the future. AI will code for us in the future. Data is one
thing which I bet on, second is how we think and how we use AI for our
betterment and betterment of the society. We dream of humans and AI
working together as companions making world a better place.
It
is our responsibility to shape it well, so that it doesn’t go rogue.
Our curiosity will lead us there. One day we will reach there, true AGI.
This is what we need:
Open Source tools and libraries
Open source datasets to encourage developers
Open educational material like videos, tutorials, articles and easy to unserstand description of research papers.
Open groups to discuss AI/DL and community building.
All
of the above do exist in some form, what is not there is a tool for
masses to play around with ML/DL and contribute back to the society.
Until now.
A revolution is happening right now, the whole world is embracing it. Mate Labs
wants to be there as one shoulder for people to bank on and fuel this
revolution by enabling everyone with the right tools, libraries,
datasets and educational materials. We believe in building a community
of enthusiasts, curious and thirsty folks standing for innovation and a bright future.
We have open sourced the implementation of All Convolutional Networks
which is available on Github. We have also published a suite of
easy-to-run scripts to install Tensorflow and Docker on your system to
get you started. More to come soon.
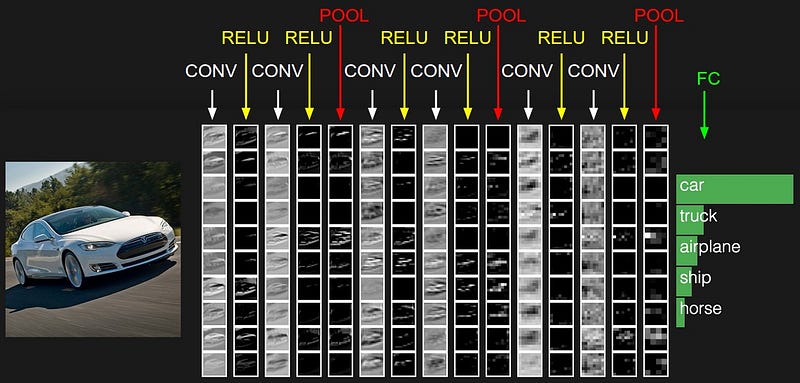
Most modern convolutional neural networks (CNNs) used for object recognition
are built using the same principles: Alternating convolution and max-pooling
layers followed by a small number of fully connected layers. We re-evaluate the
state of the art for object recognition from small images with convolutional
networks, questioning the necessity of different components in the pipeline. We
find that max-pooling can simply be replaced by a convolutional layer with
increased stride without loss in accuracy on several image recognition
benchmarks. Following this finding -- and building on other recent work for
finding simple network structures -- we propose a new architecture that
consists solely of convolutional layers and yields competitive or state of the
art performance on several object recognition datasets (CIFAR-10, CIFAR-100,
ImageNet). To analyze the network we introduce a new variant of the
"deconvolution approach" for visualizing features learned by CNNs, which can be
applied to a broader range of network structures than existing approaches.
mages
are nothing but a collection of pixel values and this idea was
leveraged by the Computer scientist and researcher to build a Neural
Network which is an analogy of the Human Brain and achieve exceptional
results (sometimes even better than Human level accuracy).
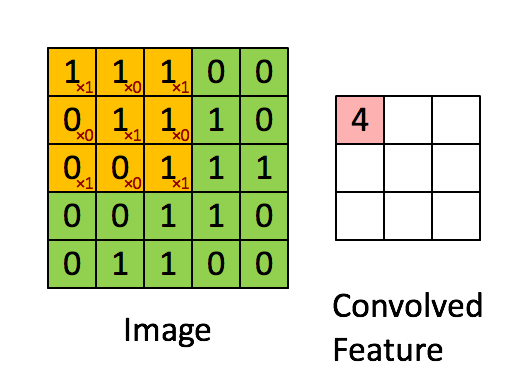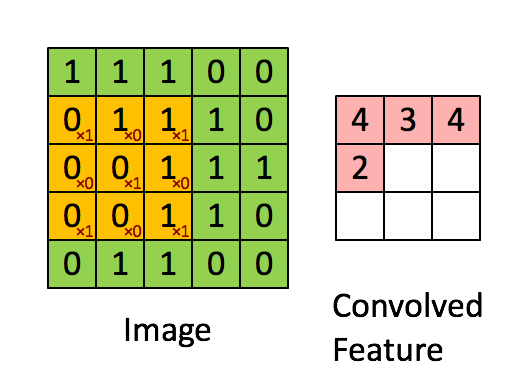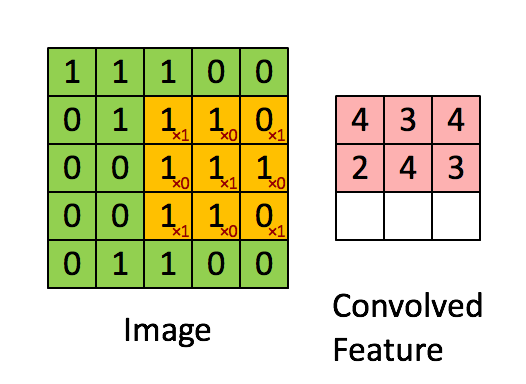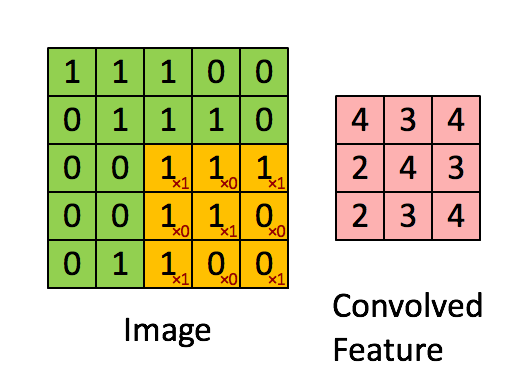
A
very good example of how images are represented as pixels. These small
pixels forms the basis of Convolution Neural Network. Pic Courtesy: Adam Geitgey (via medium.com)
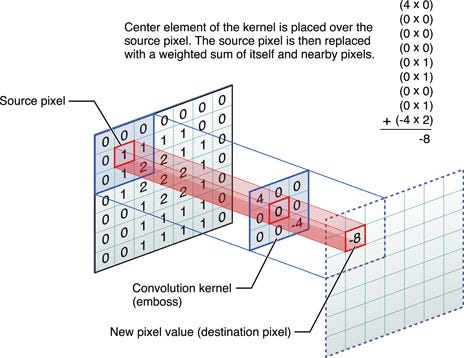
Convolution Neural Networks are very similar to ordinary Neural Networks as they are made up of neurons that have learn-able weights and biases. Each neuron receives some inputs, performs a dot (scalar) product and optionally follows it with a non-linearity.
The whole network still expresses a single differentiable score
function, from the raw image pixels on one end to class scores at the
other. And they still have a loss function, to calculate relative
probability (e.g. SVM/Softmax) after the last (fully-connected) layer and all the tips/tricks developed for learning regular Neural Networks still apply.
In
recent times with the rise of data and computational power, ConvNets
have been extremely successful in identifying faces, different objects
and traffic signs apart from powering vision in robots and self driving
cars and a lot more.
A image of a Car is passed through the ConNet and at the end of the fully connected layer it classifies as Car. Pic Courtesy: Andrew Karapathy (CS231 Blog)
Most
modern convolution neural networks (CNNs) used for object recognition
are built using the same principles: Alternating convolution and
max-pooling layers followed by a small number of fully connected layers.
Now in a recent paper it was noted that max-pooling can simply be
replaced by a convolution layer with an increased stride without loss in
accuracy on several image recognition benchmarks. Also the next
interesting thing mentioned in the paper was removing the Fully
Connected layer and put a Global Average pooling instead.
Removing
the Fully Connected layer may not seem that big of a surprise to
everybody, people have been doing the “no FC layers” thing for a long
time now. Yann LeCun even mentioned it on Facebook a while back — he has been doing it since the beginning.
Intuitively
this makes sense, the Fully connected network are nothing but
Convolution layers with the only difference is that the neurons in the
Convolution layers are connected only to a local region in the input,
and that many of the neurons in a Conv volume share parameters. However,
the neurons in both layers still compute dot products, so their
functional form is identical. Therefore, it turns out that it’s possible
to convert between FC and CONV layers and sometimes replace FC with
Conv layers
As
mentioned, the next thing is removing the spatial pooling operation
from the network, now this may raise few eyebrows. Let’s take a closer
look at this concept.
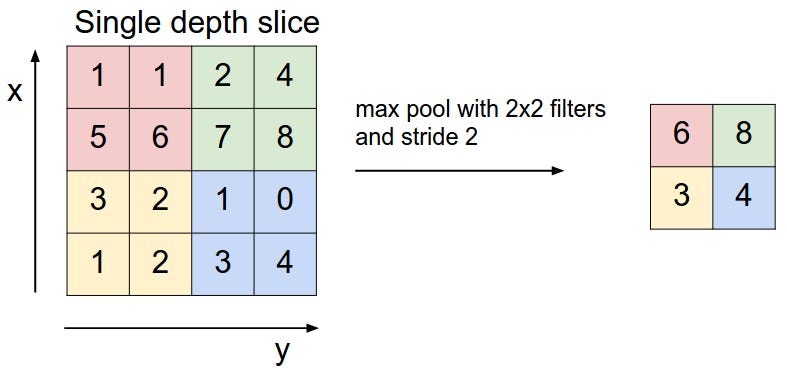
The
spatial Pooling (also called subsampling or downsampling) reduces the
dimensionality of each feature map but retains the most important
information.
For
example, let’s consider Max Pooling. In case of Max Pooling, we define a
spatial window and take the largest element from the feature map within
that window. Now remember How Convolution works
(Fig. 2). Intuitively the convolution layer with higher strides can
serve as subsampling and downsampling layer it can make the input
representations smaller and more manageable. Also it can reduce the
number of parameters and computations in the network, therefore,
controllingthings like overfitting.
To
reduce the size of the representation using larger stride in CONV layer
once in a while can always be a preferred option in many cases.
Discarding pooling layers has also been found to be important in
training good generative models, such as variational autoencoders (VAEs) or generative adversarial networks (GANs). Also it seems likely that future architectures will feature very few to no pooling layers.
from __future__ import print_function
import tensorflow as tf
from keras.datasets import cifar10
from keras.preprocessing.image import ImageDataGenerator
from keras.models import Sequential
from keras.layers import Dropout, Activation, Convolution2D, GlobalAveragePooling2D
from keras.utils import np_utils
from keras.optimizers import SGD
from keras import backend as K
from keras.models import Model
from keras.layers.core import Lambda
from keras.callbacks import ModelCheckpoint
import pandas
Training on multi GPU
For
Multi GPU implementation of the model, we have a custom function that
distributes the data for training into the available GPU(s).
The computation is done on the GPU and the outputs are merged on the CPU to complete the model.
#Place a copy of the model on each GPU, each getting a slice of the batch
for i in range(gpu_count):
with tf.device('/gpu:%d' % i):
with tf.name_scope('tower_%d' % i) as scope:
inputs = []
#Slice each input into a piece for processing on this GPU
for x in model.inputs:
input_shape = tuple(x.get_shape().as_list())[1:]
slice_n = Lambda(get_slice, output_shape=input_shape, arguments={'idx':i,'parts':gpu_count})(x)
inputs.append(slice_n)
outputs = model(inputs)
if not isinstance(outputs, list):
outputs = [outputs]
#Save all the outputs for merging back together later
for l in range(len(outputs)):
outputs_all[l].append(outputs[l])
# merge outputs on CPU
with tf.device('/cpu:0'):
merged = []
for outputs in outputs_all:
merged.append(merge(outputs, mode='concat', concat_axis=0))
return Model(input=model.inputs, output=merged)
Configuring batch size, number of classes and the no of iterations
Since we are going with CIFAR 10
which has 10 classes (categories of different object)so the Number of
classes are 10, the batch size is equal to 32 . And the number of
iterations depends upon the time you have and the computation power. For
this example we are going with 1000
The size of the images are 32*32 and the channels = 3 (rgb)
Printing
the model. This gives you the summary of the model, it is very helpful
for visualising the dimensions and the number of parameters of your
model
print (model.summary())
Data augmentation
datagen = ImageDataGenerator(
featurewise_center=False, # set input mean to 0 over the dataset
samplewise_center=False, # set each sample mean to 0
featurewise_std_normalization=False, # divide inputs by std of the dataset
samplewise_std_normalization=False, # divide each input by its std
zca_whitening=False, # apply ZCA whitening
rotation_range=0, # randomly rotate images in the range (degrees, 0 to 180)
width_shift_range=0.1, # randomly shift images horizontally (fraction of total width)
height_shift_range=0.1, # randomly shift images vertically (fraction of total height)
horizontal_flip=False, # randomly flip images
vertical_flip=False) # randomly flip images
datagen.fit(X_train)
Saving the best weights and adding checkpoints into our model
The
above model easily achieves more than 90% accuracy after the first 350
iterations. If you want to increase the accuracy then you can try much
more heavy data augmentation at the cost of computation time.
Alternatively, if all you want is to use a model trained on ALL-CNN (described above), sign-up for Mateverse, and you’ll be able to train a fresh model instantly.
Square pegs don’t fit in round holes, but what if you have power tools?
Digital images often don’t fit where we want them: advertisements, social
networks, and printers all require that images be a specific aspect ratio
(i.e., the ratio of the image’s width to height). Take Facebook
ads for example:
different aspect ratios are required depending on what kind of ad you wish to
run. This is a large pain point for marketers: each piece of content must be
manually cropped to fit the aspect ratio of the channel. Typically, images are
either padded with white pixels (thus wasting valuable screen real estate) or
arbitrarily cropped (possibly degrading the content).
But it doesn’t have to be this way! In this post, we present a technique that we
use for intelligent cropping: a fully automatic method that preserves the
image’s content. We’ve included some example code so you can explore on your
own, and some real-world examples from Curalate’s products.
The following illustrates our approach:
The input to the algorithm is an image and a desired aspect ratio.
First, we use a variety of techniques to detect different types of content in
the image. Each technique results in a number of content rectangles that are
assigned a value score.
Second, we select the optimal region of the image as that which contains the
content rectangles with the higest cumulative score.
Finally, we crop the input image to the optimal region.
The result is a cropped image of the desired aspect ratio fully containing the
content in the image.
To run these examples for yourself, you’ll need Python 2 with OpenCV, NumPy, and
matplotlib installed. The images used for examples in this post may be
downloaded here.
This entire post is also available as a python notebook if you want to
take it for a spin.
To start off, let’s load an image we’d like to use:
Let’s assume we’re creating a Facebook ad to drive traffic to our website. The
recommended resolution
is 1200x628 for target aspect ratio of 1.91.
The naive approach would just crop the center of the image:
Ugh. I wouldn’t click on that. Let’s do something intelligent!
Identifying Content in Images
Our first task is to detect different content in the image. Object detection is
still an active area of research, though recent
advances have started to make it feasible in
many applications. Here we explore a few simple techniques that are built into
OpenCV but you can use any detector you like.
Face Detection
If an image contains a face, it’s likely that the person is a key element in the
image. Fortunately, face detection is a common task in computer vision:
Sometimes, we don’t know what we’re looking for in an image. Low-level image
characteristics, however, often correspond to the interesting area of images.
There are many common techniques for identifying interesting areas of an image,
even ones that estimate visual saliency. Shi-Tomasi’s Good Features To
Track is one
technique commonly used to indicate interest points in an image. Detecting these
interest points is also relatively simple using OpenCv:
Other times, we know a specific product is in an image and we want to make sure
we don’t crop it out. We can achieve this by localizing an image of the product
in our image of interest.
In our example, the product is:
We can locate the product in the image using instance retrieval techniques.
First, we’ll estimate the transformation between the product and the target
image:
The result is a set of correspondence points between the images:
defdrawMatches(img1,kpts1,img2,kpts2,matches):# combine both imagesout=np.zeros((max([img1.shape[0],img2.shape[0]]),img1.shape[1]+img2.shape[1],3),dtype='uint8')out[:img1.shape[0],:img1.shape[1]]=img1out[:img2.shape[0],img1.shape[1]:]=img2# draw the linesformatchinmatches:(x1,y1)=kpts1[match.queryIdx].pt(x2,y2)=kpts2[match.trainIdx].ptcv2.line(out,(int(x1),int(y1)),(int(x2)+img1.shape[1],int(y2)),(0,0,255),4)returnoutshowImage(drawMatches(productImage,kpts1,img,kpts2,np.array(matches)[[np.where(mask.ravel()==1)[0]]]))
We simply take the bounding box around the product’s location:
Now that we have detected the content regions in the image, we’d like to
identify the best way to crop the image to a desired aspect ratio of 1.91. The
strategy is simple: find the area of the image with the desired aspect ratio
containing the highest sum of the content rectangle scores.
First, let’s assign a score to each content rectangle. For this example, we’ll
just use the area of each rectangle.
Now for the fun part:
Depending on the input image and desired aspect ratio, the resulting crop will
either have the same height as the input image and a reduced width, or the same
width as the input image and a reduced height. The principal axis is the
dimension of the input image that needs to be cropped. Let:
alpha=img.shape[1]/float(img.shape[0])
be the aspect ratio of the input image. If alpha > desiredAspectRatio, then
the horizontal axis is the principal axis and the system crops the width of the
image. Similarly, if alpha < desiredAspectRatio, then the vertical axis is the
principal axis and the system crops the height of the image.
Projecting the content rectangles onto the principal axis simplifies our goal:
the optimal crop is simply the window along the principal axis containing the
highest sum of content region scores. The length of this window is the size of
the final crop along the principal axis.
if(alpha>desiredAspectRatio):# the horizontal axis is the principal axis.finalWindowLength=int(desiredAspectRatio*img.shape[0])projection=np.array([[1,0,0,0],[0,0,1,0]])else:# the vertical axis is the principal axis.finalWindowLength=int(img.shape[1]/desiredAspectRatio)projection=np.array([[0,1,0,0],[0,0,0,1]])contentRegions=np.dot(projection,contentRectangles.T).T
Thus, the content rectangles are reduced from two dimensional rectangles to one
dimensional regions.
Selecting the Optimal Crop
The optimal crop is the window of length finalWindowLength whose
contentRegions’ scores sum to the largest possible value. We can use a sliding
window approach to quickly and efficiently find such a crop.
First, we’ll define the inflection points for the sliding window approach.
Each inflection point is a location on the number line where the value of the
current window can change. There are two inflection points for each content
region: one that removes the content region’s score when the window passes the
region’s starting location, and one that adds a content region’s score when the
window encapsulates it.
Next, we’ll sort the inflection points by their locations on the number line,
and ignore any outside the valid range:
inflections=inflections[inflections[:,0].argsort()]# Sort by locationinflections=inflections[inflections[:,0]>=0]# drop any outside our range
To implement our sliding window algorithm, we need only accumulate the sum of
the inflection points’ values at each location, and then take the maximum:
The optimalInflectionPoint contains a starting location that has the most
value. In fact the range of pixels between that inflection point and the next
one all have that same value. We’ll take the middle of that range for our
starting point:
Awesome! Now we know where to crop the image! You can see below that the optimal
crop indeed includes the product, the face, and a large number of the interest
points:
Now that’s a good pic!
Disclaimer: The code above is meant as a demonstration. Optimization, handling
of edge cases, and parameter tuning are left as an exercise for the reader 😉.
Result Gallery
Below are some example results. The desired aspect ratio is listed below the
input image.
Uses in Curalate Products
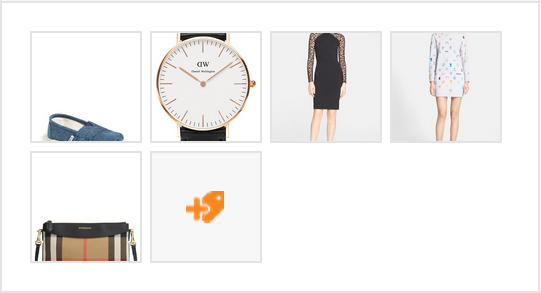
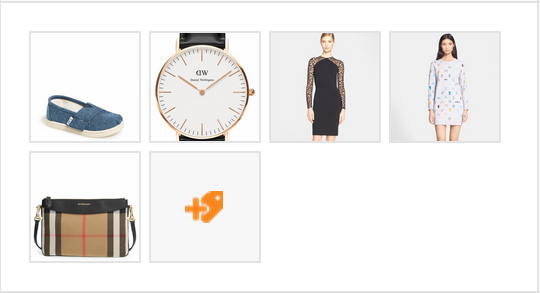
One great place we use intelligent cropping is when displaying our clients’
images. Below is a screenshot showing some product images before intelligent
cropping, and then after. Notice how the models’ faces, the shoe, and the bag
were all cropped using the naive method. After intelligent cropping, our
thumbnails are much more useful representations of the original images.
Before Intelligent Cropping
After Intelligent Cropping
Lou Kratz
is the Lead Research Engineer at Curalate. He received
his PhD in computer vision from Drexel University in 2012, and then got
hit by the start-up bug in the best way. He enjoys making cool stuff
using computer vision and machine learning when he's not cooking,
watching Jeopardy, or playing bocce. He lives in Philadelphia which he
used as a primary subject for his instagram account, at least until his
daughter was born.
Posted by David Ha, Google Brain Resident
Abstract visual communication is a key part of how people convey ideas
to one another. From a young age, children develop the ability to depict
objects, and arguably even emotions, with only a few pen strokes. These
simple drawings may not resemble reality as captured by a photograph,
but they do tell us something about how people represent and reconstruct
images of the world around them.
Machine Learning is Fun! The world’s easiest introduction to Machine Learning https://medium.com/@ageitgey/machine-learning-is-fun-80ea3ec3c471
2 Machine Learning is Fun! Part 2 Using Machine Learning to generate Super Mario Maker levels https://medium.com/@ageitgey/machine-learning-is-fun-part-2-a26a10b68df3
3 Machine Learning is Fun! Part 3: Deep Learning and Convolutional Neural Networks https://medium.com/@ageitgey/machine-learning-is-fun-part-3-deep-learning-and-convolutional-neural-networks-f40359318721
4 Machine Learning is Fun! Part 4: Modern Face Recognition with Deep Learning https://medium.com/@ageitgey/machine-learning-is-fun-part-4-modern-face-recognition-with-deep-learning-c3cffc121d78
6 Machine Learning is Fun Part 6: How to do Speech Recognition with Deep Learning https://medium.com/@ageitgey/machine-learning-is-fun-part-6-how-to-do-speech-recognition-with-deep-learning-28293c162f7a