https://towardsdatascience.com/boruta-explained-the-way-i-wish-someone-explained-it-to-me-4489d70e154a
Boruta Explained Exactly How You Wished Someone Explained to You
Looking under the hood of Boruta, one of the most effective feature selection algorithms

Feature selection is a fundamental step in many machine learning pipelines. You dispose of a bunch of features and you want to select only the relevant ones and to discard the others. The aim is simplifying the problem by removing unuseful features which would introduce unnecessary noise (ever heard of Occam?).
Boruta is a pretty smart algorithm dating back to 2010 designed to automatically perform feature selection on a dataset. It was born as a package for R (this is the article that first described it). A version of Boruta for Python — called BorutaPy — exists and can be found here.
In this post, we will see some straightforward Python code for implementing Boruta from scratch — I believe that building something from scratch is the best way to really understand it — and, at the end of the post, we will see how to use BorutaPy to make our life easier.
1. It all starts with X and y
In order to see Boruta in action, let’s build a toy dataset with 3 features (age, height and weight), a target variable (income) and 5 observations.
import pandas as pd### make X and y
X = pd.DataFrame({'age': [25, 32, 47, 51, 62],
'height': [182, 176, 174, 168, 181],
'weight': [75, 71, 78, 72, 86]})
y = pd.Series([20, 32, 45, 55, 61], name = 'income')

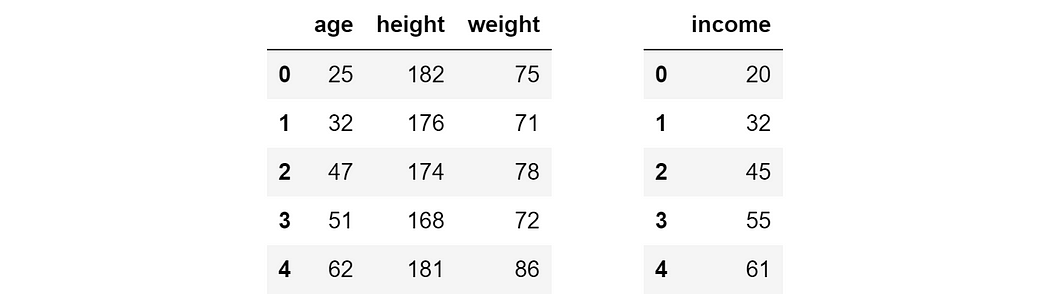
So the goal is to predict the income of a person knowing his/her age, height and weight. This may seem nonsensical (at least in theory: in practice, height has been proven to be related to salary), but in general it’s advisable not to be influenced by one’s bias.
In a real-life situation, we would have to deal with more than 3 features (from some hundreds to many thousands, typically). Thus, it would be unfeasible to go through each of them and decide whether to keep it or not. Moreover, there are relationships (such as non linear relationships and interactions) that are not easily spotted by a human eye, not even with accurate analysis.
Ideally, we would like to find an algorithm that is able to autonomously decide whether any given feature of X bears some predictive value about y.
2. Why Boruta?
A popular algorithm for feature selection is sklearn’s SelectFromModel. Basically, you choose a model of convenience — capable of capturing non-linear relationships and interactions, e.g. a random forest — and you fit it on X and y. Then, you extract the importance of each feature from this model and keep only the features that are above a given threshold of importance.
This sounds reasonable, but the weak spot of such an approach is self-evident: who determines the threshold, and how? There is a good deal of arbitrariness in it.
When I first crashed into this problem, I started looking for a more robust solution. Until I found Boruta. Boruta is a feature selection algorithm which is statistically grounded and works extremely well even without any specific input by the user. How is that even possible?
Boruta is based on two brilliant ideas.
2.1 The first idea: shadow features
In Boruta, features do not compete among themselves. Instead — and this is the first brilliant idea — they compete with a randomized version of them.
In practice, starting from X, another dataframe is created by randomly shuffling each feature. These permuted features are called shadow features. At this point, the shadow dataframe is attached to the original dataframe to obtain a new dataframe (we will call it X_boruta), which has twice the number of columns of X.
import numpy as np### make X_shadow by randomly permuting each column of X
np.random.seed(42)
X_shadow = X.apply(np.random.permutation)
X_shadow.columns = ['shadow_' + feat for feat in X.columns]### make X_boruta by appending X_shadow to X
X_boruta = pd.concat([X, X_shadow], axis = 1)
This is how X_boruta would look like in our case:


Then, a random forest is fitted on X_boruta and y.
Now, we take the importance of each original features and compare it with a threshold. This time, the threshold is defined as the highest feature importance recorded among the shadow features. When the importance of a feature is higher than this threshold, this is called a “hit”. The idea is that a feature is useful only if it’s capable of doing better than the best randomized feature.
The code to reproduce this process is the following
from sklearn.ensemble import RandomForestRegressor### fit a random forest (suggested max_depth between 3 and 7)
forest = RandomForestRegressor(max_depth = 5, random_state = 42)
forest.fit(X_boruta, y)### store feature importances
feat_imp_X = forest.feature_importances_[:len(X.columns)]
feat_imp_shadow = forest.feature_importances_[len(X.columns):]### compute hits
hits = feat_imp_X > feat_imp_shadow.max()
For our toy dataset, the outcome is:


The threshold is 14% (maximum of 11%, 14% and 8%), thus 2 features made a hit, namely age and height (respectively 39% and 19%), whereas weight (8%) scored below the threshold.
Apparently, we should drop weight and get on with age and height. But should we trust this run? What if it was just an unlucky run for weight? What if instead it was just a lucky run for age and height?
This is where the second brilliant idea of Boruta comes into play.
2.2 The second idea: binomial distribution
As often happens in machine learning (in life?), the key is iteration. Not surprisingly, 20 trials are more reliable than 1 trial and 100 trials are more reliable than 20 trials.
For instance, let’s repeat for 20 times the process seen above.
### initialize hits counter
hits = np.zeros((len(X.columns)))### repeat 20 times
for iter_ in range(20): ### make X_shadow by randomly permuting each column of X
np.random.seed(iter_)
X_shadow = X.apply(np.random.permutation)
X_boruta = pd.concat([X, X_shadow], axis = 1) ### fit a random forest (suggested max_depth between 3 and 7)
forest = RandomForestRegressor(max_depth = 5, random_state = 42)
forest.fit(X_boruta, y) ### store feature importance
feat_imp_X = forest.feature_importances_[:len(X.columns)]
feat_imp_shadow = forest.feature_importances_[len(X.columns):] ### compute hits for this trial and add to counter
hits += (feat_imp_X > feat_imp_shadow.max())
This is the outcome:


Now, how do we set a decision criterion? This is the second brilliant idea contained in Boruta.
Let’s take a feature (no matter if age, height or weight) and say we have absolutely no clue if it’s useful or not. What is the probability that we shall keep it? The maximum level of uncertainty about the feature is expressed by a probability of 50%, like tossing a coin. Since each independent experiment can give a binary outcome (hit or no hit), a series of n trials follows a binomial distribution.
In Python, the probability mass function of a binomial distibution can be computed as follows:
import scipy as sptrials = 20
pmf = [sp.stats.binom.pmf(x, trials, .5) for x in range(trials + 1)]
These values look like a bell:


In Boruta, there is not a hard threshold between a refusal and an acceptance area. Instead, there are 3 areas:
- an area of refusal (the red area): the features that end up here are considered as noise, so they are dropped;
- an area of irresolution (the blue area): Boruta is indecisive about the features that are in this area;
- an area of acceptance (the green area): the features that are here are considered as predictive, so they are kept.
The areas are defined by selecting the two most extreme portions of the distribution called tails of the distribution (in our example each tail accounts for 0.5% of the distribution).
So, we did 20 iterations on our toy data and ended up with some statistically grounded conclusions:
- in order to predict the income of a person, age is predictive and should be kept, weight is just noise and should be dropped,
- Boruta was indecisive about height: the choice is up to us, but in a conservative frame, it is advisable to keep it.
In this paragraph, we have implemented the necessary code, but a great (optimized) library for Boruta in Python exists.
3. Using BorutaPy in Python
Boruta can be installed via pip:
!pip install borutaThis is how it can be used:
from boruta import BorutaPy
from sklearn.ensemble import RandomForestRegressor
import numpy as np###initialize Boruta
forest = RandomForestRegressor(
n_jobs = -1,
max_depth = 5
)
boruta = BorutaPy(
estimator = forest,
n_estimators = 'auto',
max_iter = 100 # number of trials to perform
)### fit Boruta (it accepts np.array, not pd.DataFrame)
boruta.fit(np.array(X), np.array(y))### print results
green_area = X.columns[boruta.support_].to_list()
blue_area = X.columns[boruta.support_weak_].to_list()print('features in the green area:', green_area)
print('features in the blue area:', blue_area)
As you can see, the features stored in boruta.support_ are the ones that at some point ended up in the acceptance area, thus you should include them in your model. The features stored in boruta.support_weak_ are the ones that Boruta didn’t manage to accept or refuse (blue area) and the choice is up to the data scientist: these features may be accepted or not depending on the use case.
4. Conclusion
Feature selection is a decisive part of a machine learning pipeline: being too conservative means introducing unnecessary noise, while being too aggressive means throwing away useful information.
In this post, we have seen how to use Boruta for performing a robust, statistically grounded feature selection on your dataset. Indeed, making substantial decisions about features is critical to ensure the success of your predictive model.