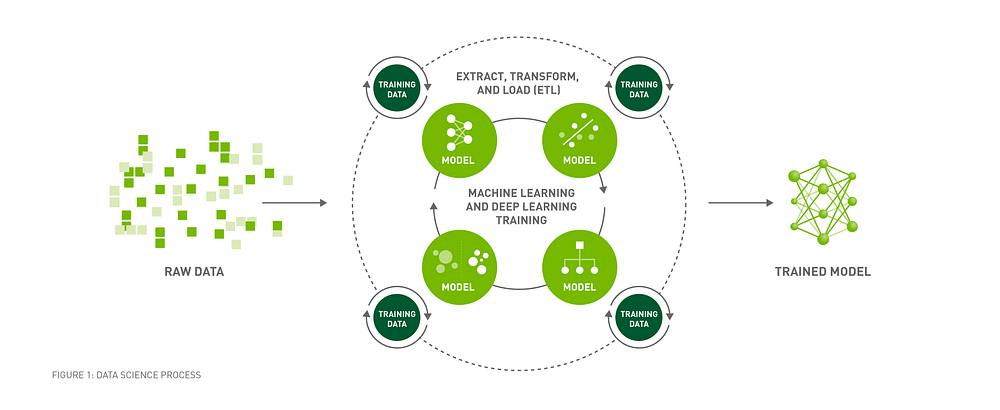
Data science can have transformative effects on a business. But not if it takes weeks to get any results.
Putting
data science to work can be simplified into three steps. First, capture
data from your business processes. Second, combine this big data with
massive processing to create machine learning models. Third, validate
the models for accuracy and deploy them.
This almost makes it sound easy, but to date it’s been anything but. Traditional approaches like Apache Hadoop and CPU-based infrastructure aren’t up to the task — they pose too many bottlenecks and are too slow.
NVIDIA
and its partners are building GPU-based tools that let businesses
unleash data science using AI. Below are five key elements to building
AI-optimized data centers, but first let’s take a look at the crossroads
data science is at.
The Trouble with Big Data
Data
scientists implementing machine learning need three things: algorithms,
lots of data, and lots of compute power. They require terabytes of
data, petaflops of compute, and hundreds of iterative learning cycles to
create a machine learning data pipeline.
Big
data was initially built on Hadoop because it scaled easily. This
allowed tremendous amounts of data to be stored. To process this data,
software frameworks such as MapReduce were used with Hadoop across large
clusters.
However,
common data processing tasks associated with machine learning have many
steps (data pipelines), which Hadoop couldn’t handle efficiently. Apache Spark
solved this problem by holding all the data in system memory, which
allowed more flexible and complex data pipelines, but introduced new
bottlenecks.
The
many steps of these pipelines include gathering, cleaning,
standardizing and enriching data. But processing these complicated
workflows using only CPUs is prohibitively slow.
Analyzing
even a few hundred gigabytes of data could take hours if not days on
Spark clusters with hundreds of CPU nodes. Now consider processing the
terabytes of data that big data is known for, and a data scientist could
be forgiven for thinking the process had ground to a halt.
And
this doesn’t even get at the real work a data scientist wants to
perform. While a single run of a workflow is taking a few hours to
complete, data scientists in the meantime want to modify variables,
models, and model parameters to select the best combinations and iterate
their ideas.

The New Era of Data Science
To
iterate quickly, data scientists need more compute power. In fact, what
they need is supercomputing power, but in a way that enterprises can
easily integrate into existing infrastructure. Old style data centers
just aren’t going to get it done.
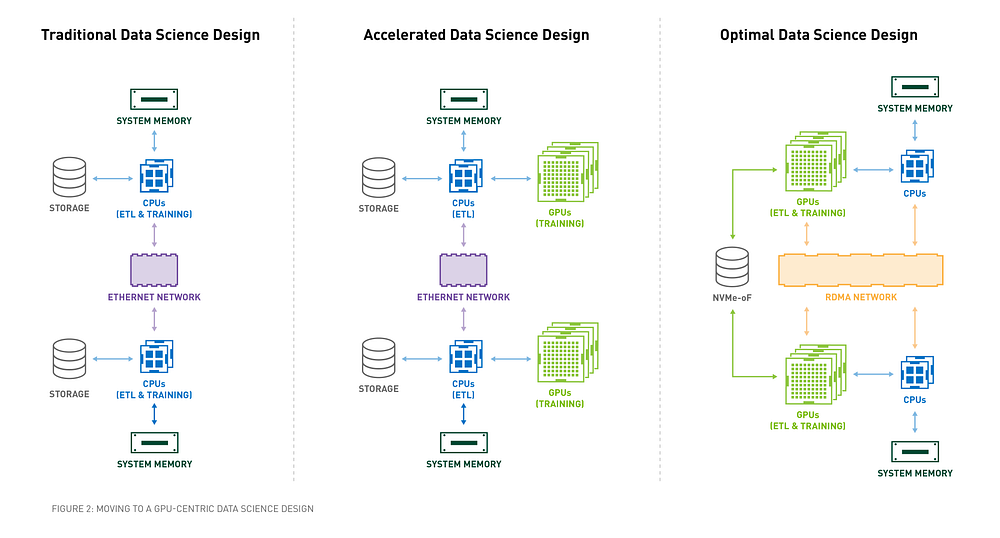
GPUs can accelerate many steps of their data pipelines. While adding GPUs to data centers provides a benefit, it’s not enough.
To
tap the potential of data science, GPUs have to be at the center of
data center design. Generally speaking, data science workflows on GPUs
are roughly 10x faster end to end than on CPUs.
We’ve
been working with our partners to create the essential building blocks
to address bottlenecks in data centers for data science. There are five
elements of the optimized AI data center:
Compute Nodes
With
their tremendous computational performance, systems with NVIDIA GPUs
are the core compute building block for AI data centers. From NVIDIA T4
to V100, NVIDIA enterprise GPUs supercharge servers across numerous
applications.
We’ve
seen a 10x-plus improvement in streaming analytic applications by
adding a single T4 per node. Elsewhere, we’ve seen 1,000x improvements
in graph analytics with V100 GPUs connected with NVSwitch in our DGX
systems.
NVIDIA
DGX systems deliver groundbreaking AI performance and lead the charge
in GPU density with eight and 16 GPUs in a single node. A single DGX-1
can replace on average 50 dual-socket CPU servers. This is the first
step to give data scientists the industry’s most powerful tools for data
exploration.
Networking
The
story doesn’t stop at scaling up from CPUs to T4 and DGX systems. With
massive data that enterprises commonly collect, data scientists also
have to scale out. Most data centers today use 10 or 25 GbE networking
because there’s almost no benefit from using anything faster. In
traditional systems GPUs communicate through standard networking. Once
data has to cross nodes, the bottleneck is the CPU and network.
Remote
direct memory access (RDMA) solves this bottleneck, providing top
performance for deep learning and machine learning. RDMA in Mellanox NICs, NCCL2 (NVIDIA collective communication library) and OpenUCX
(an open-source point to point communication framework) has led to
tremendous improvements in training speed. With RDMA allowing GPUs to
communicate directly with each other, across nodes, at up to 100Gb/s,
they can span multiple nodes and operate as if they were on one massive
server.
The
benefits of RDMA aren’t limited to training. It’s also critical for
large, complex ETL workloads. Improving networking with RDMA provides up
to a 20x benefit for distributed joins over PCIe GPU on systems without
it. In addition, formerly limited to GPU-to-GPU communication, RDMA
provides an additional 2x speed boost on ingesting data at rest with
GPUDirect Storage.
Storage
Accelerated
storage is not a new concept to enterprises, it just didn’t provide a
significant cost improvement for traditional big data clusters built on
Hadoop. Given the performance of CPUs, the answer was to use slower disk
and replicate data many times to increase locality.
But
as workloads became more complex, replication would increase. Or CPUs
would spend up to 70 percent of their time sending data back and forth
between the hundreds of nodes in a Spark cluster. While a single GPU has
at most 48GB of memory, shuffling data from storage is eventually
required, and traditional storage becomes the final bottleneck.
GPUDirect Storage
allows both NVMe and NVMe over Fabric (NVMe-oF) to read and write data
directly to the GPU, bypassing the CPU and system memory. Legacy
architectures placed a “bounce buffer” in the CPU’s system memory
between storage and GPU computing, where copies of data would be used to
keep applications on GPUs fed.
With
GPUDirect Storage, the GPU not only becomes the fastest computing
element, but also the one with the highest I/O bandwidth, once all of
the computation happens on the GPU. This frees up the CPU and system
memory for other tasks, while giving each GPU access to orders of
magnitude more data at up to 50 percent greater bandwidth.
NVSwitch unified GPUs with a system, RDMA unified GPUs across nodes, and now GPUDirect Storage unifies GPUs and NVMe to improve their capacity to petabyte scale.
Kubernetes and Containers
Deploying
software is the last key to scaling data science. Enterprises typically
rely on some virtualization or orchestration layer to deploy software.
In the data science world, Yarn long reigned supreme. It’s the backbone
of Hadoop, Spark, and the rest of the traditional big data ecosystem and
allows enterprises to switch between libraries in workflows.
Nearly
all Yarn deployments are on a version that predates GPU support. This
makes it difficult for data scientists in Yarn environments to target
GPU machines for their workloads. And it’s one of several reasons why
enterprises are moving to Kubernetes and Docker containers.
Packaging
and deploying applications via containers is critical to gaining
flexibility. Combining containerized applications with Kubernetes
enables businesses to change priorities on what task is the most
important immediately, and adds resiliency, reliability and scalability
to AI data centers. Kubernetes and containers are also faster than
traditional packaging and Yarn in deployment time. While spinning up a
data science cluster could take tens of minutes on Yarn, it can be done
in seconds with Kubernetes.
Being
able to change tasks quickly reduces idle cycles, which improves the
throughput and productivity of a cluster. As compute resources become
more powerful and dense, this is essential to maximizing the value of a
data center.
NVIDIA
realized the importance of Docker and Kubernetes and invested in this
community early. This investment has resulted in NVIDIA GPUs being a
first-class resource within Kubernetes. Software can access all the
functionality and hardware acceleration in the data center needed to
maximize corporate investments in data science.
Accelerated Software


RAPIDS
is a suite of open source software libraries and APIs for executing
data science pipelines entirely on GPUs — and can reduce training times
from days to minutes. Built on NVIDIA CUDA-X AI, RAPIDS unites years of
development in graphics, machine learning, deep learning, HPC and more.
By
hiding the complexities of working with the GPU and even the
behind-the-scenes communication protocols within the data center
architecture, RAPIDS creates a simple way to get data science done. As
more data scientists use Python and other high-level languages,
providing acceleration without code change is essential to rapidly
improving development time.
Another way to accelerate development is with integration to leading data science frameworks like Apache Spark, Dask and Numba, as well as numerous deep learning frameworks, such as PyTorch, Chainer and Apache MxNet. By doing this, RAPIDS provides the foundations of a new accelerated data science ecosystem.
As
Apache 2.0 open source software, RAPIDS not only brings together this
ecosystem on GPUs, but lowers the barrier of entry for new libraries as
well. Increasingly, products are being built on top of RAPIDS — for
example, BlazingSQL, a SQL engine (which was recently fully open-sourced) — which adds even more accelerated capabilities for users.
RAPIDS
allows a new wave of applications to have native integrations,
Kubernetes support, RDMA functionality and GPUDirect Storage across a
myriad of data formats without having to invest in years of development.
And more software makes it easier for data scientists to what they want
to do: solve challenging problems with data. Pairing these benefits
with the other facets of an AI data center lets you tackle data science
without performance limitations.
NVIDIA GPUs in Action
Regardless
of industry or use case, when putting machine learning into action,
many data science problems break down into similar steps: Iteratively
preprocessing data to build features, training models with different
parameters, and evaluating the model to ensure performance translates
into valuable results.
RAPIDS
helps accelerate all of these steps while maximizing the user’s
hardware investments. Early customers have taken full data pipelines
that took days if not weeks and ran them in minutes. They’ve
simultaneously reduced costs and improved the accuracy of their models
because more iterations allow data scientists to explore more models and
parameter combinations, as well as train on larger datasets.
Retailers
are improving their forecasting. Finance companies are better assessing
credit risk. And adtech firms are enhancing their ability to predict
click-through rates. Data scientists often achieve improvements of 1–2
percent. This may seem trivial, but it can translate to tens or hundreds
of millions of dollars of revenue and profitability.
Help Shape the Future
NVIDIA
is committed to simplifying, unifying and accelerating the data science
community. By optimizing the whole stack — from hardware to software —
and by removing bottlenecks, NVIDIA is helping data scientists
everywhere do more than ever with less. This translates into more value
for enterprises from their most precious resources: their data and data
scientists.
But,
we’re not doing this alone. Building bridges across the data science
community accelerates everyone. Be a part of the community. Start using
accelerated libraries, let us know what features should come next, and apply to join our advisory consortium.
NVIDIA is building the data science platform of the future, and we want you to be a part of it.
No comments:
Post a Comment