by Swami Sivasubramanian, Matt Wood, and Alexander Smola | on
|
Permalink |
Comments
If you ask 100 people for the definition of “artificial
intelligence,” you’ll get at least 100 answers, if not more. At AWS, we
define it as a service or system which can perform tasks that usually
require human-level intelligence such as visual perception, speech
recognition, decision making, or translation. On this new AWS blog,
we’ll be covering these areas and more, with in-depth technical content,
customer stories, and new feature announcements.
The challenges related to building sophisticated AI systems
center mostly around scale: the datasets are large, training is
computationally hungry, and inferring predictions can be challenging to
do at scale or on lower-power and mobile devices. Customers have been
using AWS to solve these general problems for years, and the ability to
be able to access storage, GPUs, CPUs, and IoT services on demand has
emerged as a perfect fit for intelligent systems in production. AWS has
become the center of gravity for AI, both at Amazon and for AWS
customers.
From computer vision systems for autonomous driving, to
FDA-approved medical imaging, AWS has driven innovation in existing
products or helped define entirely new categories of products for
customers such as Netflix, Pinterest, Airbnb, GE, Capital One, and
Wolfram Alpha. It’s also used extensively at Amazon to decrease order
delivery time with robotic fulfilment, to create novel features such as
X-ray (showing themes, characters, and their interactions in video and
text), or to bring new experiences to life such as Amazon Echo, Alexa,
or the new deep learning-powered, line-free, checkout-free grocery
store, Amazon Go (currently in beta testing in Seattle).
Our vision is to use the expertise and lessons learned from
customers and the thousands of engineers focused on AI at Amazon to put
intelligence in the hands of as many developers as possible, and that AI
should be available to everyone, irrespective of their level of
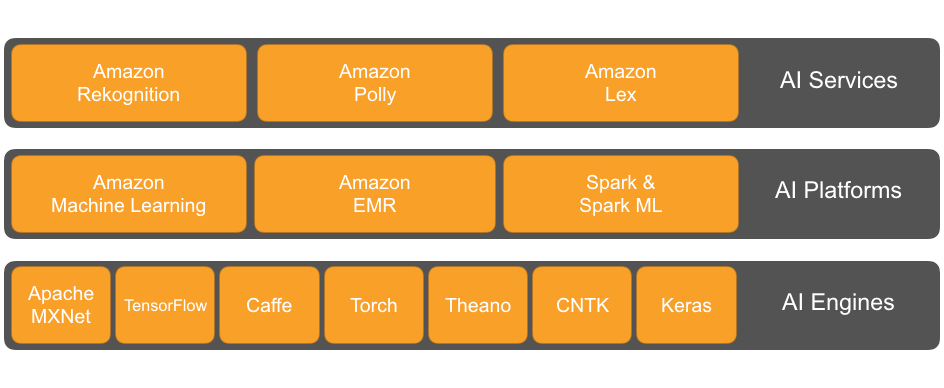
technical skill or ability. Today, our approach breaks down into three
main layers which all sit on top of the AWS infrastructure and network.
We call this, collectively, “Amazon AI.”
At the highest level, for developers who don’t currently
possess the technical skills required to implement AI models, or who
lack the high-quality, “ground truth” data to train them, we provide AI services: Amazon Rekognition for image and facial analysis, Amazon Polly for text-to-speech, and Amazon Lex,
an automatic speech recognition and natural language understanding
service for building conversational chat bots. No deep learning
expertise needed here: just visit the AWS console to get started.
One level down, for customers with existing data who want to build custom models, we provide a set of AI platforms which remove the undifferentiated heavy lifting associated with deploying and managing AI training and model hosting: Amazon Machine Learning (with both batch and real-time prediction on custom linear models) and Amazon EMR (with Spark and Spark ML support).
Finally, we provide AI engines, a
collection of open-source, deep learning frameworks for academics and
data scientists who want to build cutting edge, sophisticated
intelligent systems, pre-installed configured on a convenient machine
image. Engines such as Apache MXNet,
TensorFlow, Caffe, Theano, Torch, and CNTK provide flexible programming
models for training custom models at scale. Our favorite, and the deep
learning engine of choice at Amazon, is Apache MXNet, which scales
almost linearly across hundreds of GPUs, training efficient models which
can be run anywhere from new, custom Intel processors and
field-programmable gate arrays (FPGAs) on Amazon EC2, to AWS Lambda, to embedded devices on robots and drones.
Whether you’re in academia at the cutting edge of AI
research, or are a developer seeking simple ways to add intelligence to
your app, Amazon AI provides the broadest set of AI services, backed by a
world-class scientific and engineering team.
Today, AI is a hot topic, relevant to the majority of developers (Mark Cuban recently talked about it
as the most important technology to ramp up on, to avoid becoming a
“dinosaur”), but it’s still very early in the advent of AI. In this
blog, we’ll explore AI through tutorials, guidance, best practices, and
tips and tricks.
High-Resolution Image Inpainting using Multi-Scale Neural Patch Synthesis
This is the code for High-Resolution Image Inpainting using Multi-Scale Neural Patch Synthesis.
Given an image, we use the content and texture network to jointly infer
the missing region. This repository contains the pre-trained model for
the content network and the joint optimization code, including the demo
to run example images. The code is adapted from the Context Encoders and CNNMRF. Please contact Harry Yang for questions regarding the paper or the code. Note that the code is for research purpose only.
Download the pre-trained models for the content and texture networks and put them under the folder models/.
Run the Demo
cd High-Res-Neural-Inpainting
# This will use the trained model to generate the output of the content network
th run_content_network.lua
# This will use the trained model to run texture optimization
th run_texture_optimization.lua
# This will generate the final result
th blend.lua
Citation
If you find this code useful for your research, please cite:
@article{yang2016high,
title={High-Resolution Image Inpainting using Multi-Scale Neural Patch Synthesis},
author={Yang, Chao and Lu, Xin and Lin, Zhe and Shechtman, Eli and Wang, Oliver and Li, Hao},
journal={arXiv preprint arXiv:1611.09969},
year={2016}
}
Posted by Christian Szegedy, Software Engineer
The ImageNet large-scale visual recognition challenge (ILSVRC)
is the largest academic challenge in computer vision, held annually to
test state-of-the-art technology in image understanding, both in the
sense of recognizing objects in images and locating where they are.
Participants in the competition include leading academic institutions
and industry labs. In 2012 it was won by DNNResearch using the
convolutional neural network approach described in the now-seminal paper by Krizhevsky et al.[4]
In this year’s challenge, team GoogLeNet (named in homage to LeNet, Yann LeCun's
influential convolutional network) placed first in the classification
and detection (with extra training data) tasks, doubling the quality on
both tasks over last year's results. The team participated with an open
submission, meaning that the exact details of its approach are shared
with the wider computer vision community to foster collaboration and
accelerate progress in the field.
The competition has three tracks: classification, classification with localization, and detection. The classification track measures an algorithm’s ability to assign correct labels to an image. The classification with localization
track is designed to assess how well an algorithm models both the
labels of an image and the location of the underlying objects. Finally,
the detection challenge is similar, but uses much stricter
evaluation criteria. As an additional difficulty, this challenge
includes a lot of images with tiny objects which are hard to recognize.
Superior performance in the detection challenge requires pushing beyond
annotating an image with a “bag of labels” -- a model must be able to
describe a complex scene by accurately locating and identifying many
objects in it. As examples, the images in this post are actual
top-scoring inferences of the GoogleNet detection model on the
validation set of the detection challenge.
This work was a concerted effort by Wei Liu, Yangqing Jia, Pierre Sermanet, Scott Reed, Drago Anguelov, Dumitru Erhan, Andrew Rabinovich and myself.
Two of the team members -- Wei Liu and Scott Reed -- are PhD students
who are a part of the intern program here at Google, and actively
participated in the work leading to the submissions. Without their
dedication the team could not have won the detection challenge.
This effort was accomplished by using the DistBelief infrastructure,
which makes it possible to train neural networks in a distributed
manner and rapidly iterate. At the core of the approach is a radically
redesigned convolutional network architecture. Its seemingly complex
structure (typical incarnations of which consist of over 100 layers with
a maximum depth of over 20 parameter layers), is based on two insights:
the Hebbian principle and scale invariance.
As the consequence of a careful balancing act, the depth and width of
the network are both increased significantly at the cost of a modest
growth in evaluation time. The resultant architecture leads to over 10x
reduction in the number of parameters compared to most state of the art
vision networks. This reduces overfitting during training and allows our
system to perform inference with low memory footprint.
For the detection challenge, the improved neural network model is used in the sophisticated R-CNN detector by Ross Girshick et al.[2], with additional proposals coming from the multibox method[1]. For the classification challenge entry, several ideas from the work of Andrew Howard[3]
were incorporated and extended, specifically as they relate to image
sampling during training and evaluation. The systems were evaluated both
stand-alone and as ensembles (averaging the outputs of up to seven
models) and their results were submitted as separate entries for
transparency and comparison.
These technological advances will enable even better image understanding
on our side and the progress is directly transferable to Google
products such as photo search, image search, YouTube, self-driving cars,
and any place where it is useful to understand what is in an image as well as where things are.
References:
[1] Erhan D., Szegedy C., Toshev, A., and Anguelov, D., "Scalable Object Detection using Deep Neural Networks", The IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2014, pp. 2147-2154.
[2] Girshick, R., Donahue, J., Darrell, T., & Malik, J., "Rich feature hierarchies for accurate object detection and semantic segmentation", arXiv preprint arXiv:1311.2524, 2013.
[3] Howard, A. G., "Some Improvements on Deep Convolutional Neural Network Based Image Classification", arXiv preprint arXiv:1312.5402, 2013.
[4] Krizhevsky, A., Sutskever I., and Hinton, G., "Imagenet classification with deep convolutional neural networks", Advances in neural information processing systems, 2012.
Attacking machine learning with adversarial examples
Ian Goodfellow, Nicolas Papernot, Sandy Huang, Yan Duan, Pieter Abbeel, Jack ClarkFebruary 16, 2017
Adversarial examples are
inputs to machine learning models that an attacker has intentionally
designed to cause the model to make a mistake; they're like optical
illusions for machines. In this post we'll show how adversarial examples
work across different mediums, and will discuss why securing systems
against them can be difficult.
At OpenAI, we think adversarial examples are a good aspect of security
to work on because they represent a concrete problem in AI safety that
can be addressed in the short term, and because fixing them is difficult
enough that it requires a serious research effort. (Though we'll need
to explore many aspects of machine learning security to achieve our goal of building safe, widely distributed AI.)
To get an idea of what adversarial examples look like, consider this demonstration from Explaining and Harnessing Adversarial Examples:
starting with an image of a panda, the attacker adds a small
perturbation that has been calculated to make the image be recognized as
a gibbon with high confidence.
An adversarial input, overlaid on a typical image, can cause a classifier to miscategorize a panda as a gibbon.
The approach is quite robust; recent research
has shown adversarial examples can be printed out on standard paper
then photographed with a standard smartphone, and still fool systems.
Adversarial examples can be
printed out on normal paper and photographed with a standard resolution
smartphone and still cause a classifier to, in this case, label a
"washer" as a "safe".
Adversarial examples have the potential to be dangerous. For example,
attackers could target autonomous vehicles by using stickers or paint to
create an adversarial stop sign that the vehicle would interpret as a
'yield' or other sign, as discussed in Practical Black-Box Attacks against Deep Learning Systems using Adversarial Examples.
Reinforcement learning agents can also be manipulated by adversarial
examples, according to new research from UC Berkeley, OpenAI, and
Pennsylvania State University, Adversarial Attacks on Neural Network Policies, and research from the University of Nevada at Reno, Vulnerability of Deep Reinforcement Learning to Policy Induction Attacks. The research shows that widely-used RL algorithms, such as DQN, TRPO, and A3C,
are vulnerable to adversarial inputs. These can lead to degraded
performance even in the presence of pertubations too subtle to be
percieved by a human, causing an agent to move a pong paddle down when it should go up, or interfering with its ability to spot enemies in Seaquest.
If you want to experiment with breaking your own models, you can use cleverhans, an open source library developed jointly by Ian Goodfellow and Nicolas Papernot to test your AI's vulnerabilities to adversarial examples.
Adversarial examples give us some traction on AI safety
When we think about the study of AI safety, we usually think about some of the most
difficult problems in that field — how can we ensure that sophisticated reinforcement
learning agents that are significantly more intelligent than human beings behave in
ways that their designers intended?
Adversarial examples show us that even simple modern algorithms, for both supervised
and reinforcement learning, can already behave in surprising ways that we do not
intend.
Attempted defenses against adversarial examples
Traditional techniques for making machine learning models more robust, such as weight decay
and dropout, generally do not provide a practical defense against adversarial examples.
So far, only two methods have provided a significant defense. Adversarial training: This is a brute force solution
where we simply generate a lot of adversarial examples and explicitly
train the model not to be fooled by each of them. An open-source
implementation of adversarial training is available in the cleverhans library and its use illustrated in the following tutorial. Defensive distillation:
This is a strategy where we train the model to output probabilities of
different classes, rather than hard decisions about which class to
output. The probabilities are supplied by an earlier model, trained on
the same task using hard class labels. This creates a model whose
surface is smoothed in the directions an adversary will typically try to
exploit, making it difficult for them to discover adversarial input
tweaks that lead to incorrect categorization. (Distillation was
originally introduced in Distilling the Knowledge in a Neural Network
as a technique for model compression, where a small model is trained to
imitate a large one, in order to obtain computational savings.)
Yet even these specialized algorithms can easily be broken by giving more computational firepower to the attacker.
A failed defense: “gradient masking”
To give an example of how a simple defense can fail, let's consider why a technique called "gradient masking" does not work.
"Gradient masking" is a term introduced in Practical Black-Box Attacks against Deep Learning Systems using Adversarial Examples. to describe an entire category of failed defense methods that work by trying to deny the attacker access to a useful gradient.
Most adversarial example construction techniques use the gradient of the
model to make an attack. In other words, they look at a picture of an
airplane, they test which direction in picture space makes the
probability of the “cat” class increase, and then they give a little
push (in other words, they perturb the input) in that direction. The
new, modified image is mis-recognized as a cat.
But what if there were no gradient — what if an infinitesimal
modification to the image caused no change in the output of the model?
This seems to provide some defense because the attacker does not know
which way to “push” the image.
We can easily imagine some very trivial ways to get rid of the gradient.
For example, most image classification models can be run in two modes:
one mode where they output just the identity of the most likely class,
and one mode where they output probabilities. If the model’s output is
“99.9% airplane, 0.1% cat”, then a little tiny change to the input gives
a little tiny change to the output, and the gradient tells us which
changes will increase the probability of the “cat” class. If we run the
model in a mode where the output is just “airplane”, then a little tiny
change to the input will not change the output at all, and the gradient
does not tell us anything.
Let’s run a thought experiment to see how well we could defend our model
against adversarial examples by running it in “most likely class” mode
instead of “probability mode.” The attacker no longer knows where to go
to find inputs that will be classified as cats, so we might have some
defense. Unfortunately, every image that was classified as a cat before
is still classified as a cat now. If the attacker can guess which points
are adversarial examples, those points will still be misclassified. We
haven’t made the model more robust; we have just given the attacker
fewer clues to figure out where the holes in the models defense are.
Even more unfortunately, it turns out that the attacker has a very good
strategy for guessing where the holes in the defense are. The attacker
can train their own model, a smooth model that has a gradient, make
adversarial examples for their model, and then deploy those adversarial
examples against our non-smooth model. Very often, our model will
misclassify these examples too. In the end, our thought experiment
reveals that hiding the gradient didn’t get us anywhere.
The defense strategies that perform gradient masking typically result in
a model that is very smooth in specific directions and neighborhoods of
training points, which makes it harder for the adversary to find
gradients indicating good candidate directions to perturb the input in a
damaging way for the model. However, the adversary can train a substitute
model: a copy that imitates the defended model by observing the labels
that the defended model assigns to inputs chosen carefully by the
adversary.
A procedure for performing such a model extraction attack was introduced
in the black-box attacks paper. The adversary can then use the
substitute model’s gradients to find adversarial examples that are
misclassified by the defended model as well. In the figure above,
reproduced from the discussion of gradient masking found in Towards the Science of Security and Privacy in Machine Learning,
we illustrate this attack strategy with a one-dimensional ML problem.
The gradient masking phenomenon would be exacerbated for higher
dimensionality problems, but harder to depict.
We find that both adversarial training and defensive distillation
accidentally perform a kind of gradient masking. Neither algorithm was
explicitly designed to perform gradient masking, but gradient masking is
apparently a defense that machine learning algorithms can invent
relatively easily when they are trained to defend themselves and not
given specific instructions about how to do so. If we transfer
adversarial examples from one model to a second model that was trained
with either adversarial training or defensive distillation, the attack
often succeeds, even when a direct attack on the second model would
fail. This suggests that both training techniques do more to flatten out
the model and remove the gradient than to make sure it classifies more
points correctly.
Why is it hard to defend against adversarial examples?
Adversarial examples are hard to defend against because it is difficult
to construct a theoretical model of the adversarial example crafting
process. Adversarial examples are solutions to an optimization problem
that is non-linear and non-convex for many ML models, including neural
networks. Because we don’t have good theoretical tools for describing
the solutions to these complicated optimization problems, it is very
hard to make any kind of theoretical argument that a defense will rule
out a set of adversarial examples.
Adversarial examples are also hard to defend against because they require machine learning models to produce good outputs for every possible input.
Most of the time, machine learning models work very well but only work
on a very small amount of all the many possible inputs they might
encounter.
Every strategy we have tested so far fails because it is not adaptive:
it may block one kind of attack, but it leaves another vulnerability
open to an attacker who knows about the defense being used. Designing a
defense that can protect against a powerful, adaptive attacker is an
important research area.
Conclusion
Adversarial examples show that many modern machine learning algorithms
can be broken in surprising ways. These failures of machine learning
demonstrate that even simple algorithms can behave very differently from
what their designers intend. We encourage machine learning researchers
to get involved and design methods for preventing adversarial examples,
in order to close this gap between what designers intend and how
algorithms behave. If you're interested in working on adversarial
examples, consider joining OpenAI.
For more information
To learn more about machine learning security, follow Ian and Nicolas's machine learning security blog cleverhans.io.
At SVDS, our R&D team has been investigating different deep learning technologies, from recognizing images of trains
to speech recognition. We needed to build a pipeline for ingesting
data, creating a model, and evaluating the model performance. However,
when we researched what technologies were available, we could not find a
concise summary document to reference for starting a new deep learning
project.
One way to give back to the open source community that provides us
with tools is to help others evaluate and choose those tools in a way
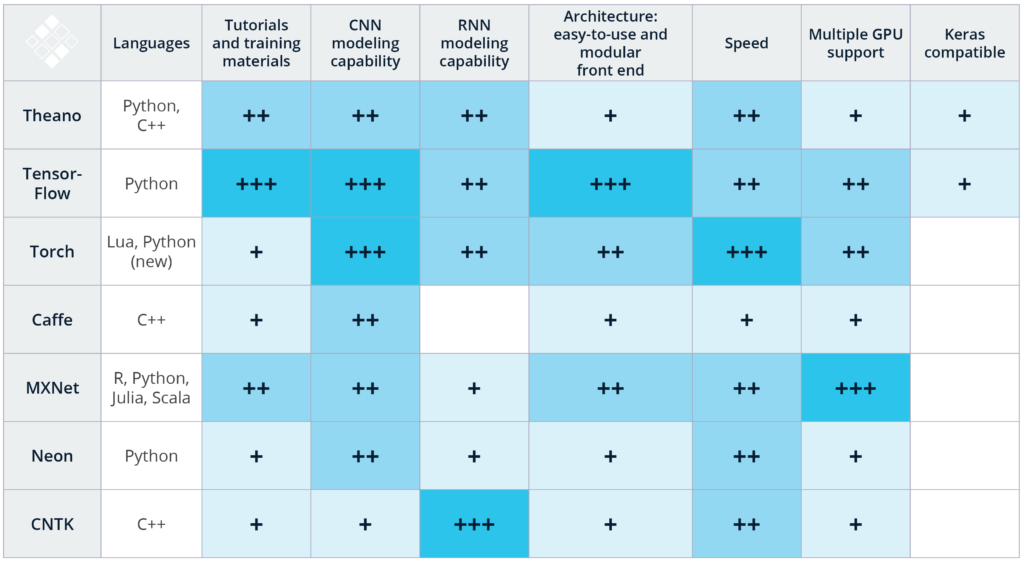
that takes advantage of our experience. We offer the chart below, along
with explanations of the various criteria upon which we based our
decisions.
These rankings are a combination of our subjective experiences with
image and speech recognition applications for these technologies, as
well as publicly available benchmarking studies. We explain our scoring
below: Languages: When getting started with deep learning,
it is best to use a framework that supports a language you are familiar
with. For instance, Caffe (C++) and Torch (Lua) have Python bindings for
its codebase (with PyTorch being released in January 2017),
but we would recommend that you are proficient with C++ or Lua
respectively if you would like to use those technologies. In comparison,
TensorFlow and MXNet have great multi language support that make it
possible to utilize the technology even if you are not proficient with
C++. Tutorials and Training Materials: Deep learning
technologies vary dramatically in the quality and quantity of tutorials
and getting started materials. Theano, TensorFlow, Torch, and MXNet have
well documented tutorials that are easy to understand and implement.
While Microsoft’s CNTK and Intel’s Nervana Neon are powerful tools, we
struggled to find beginner-level materials. Additionally, we’ve found
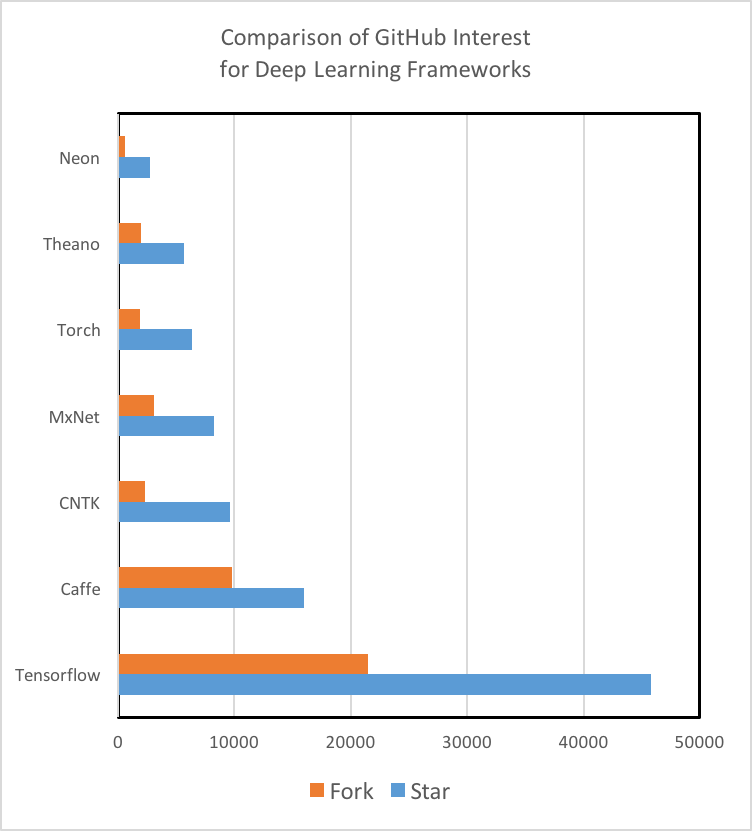
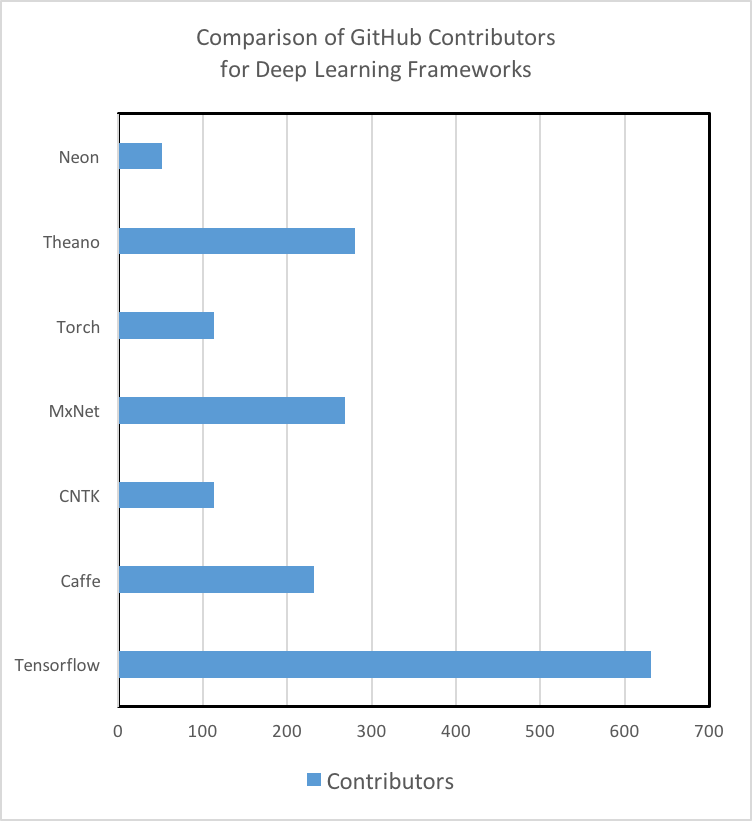
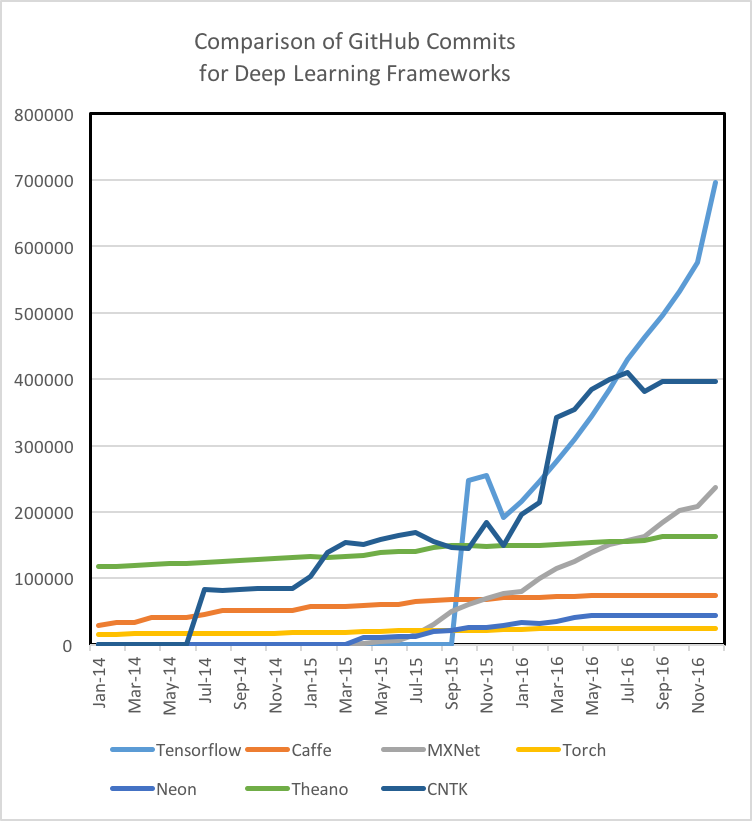
that the engagement of the GitHub community is a strong indicator of not
only a tool’s future development, but also a measure of how likely/fast
an issue or bug can be solved through searching StackOverflow or the
repo’s Git Issues. It is important to note that TensorFlow is the
800-pound Gorilla in the room in regards to quantity of tutorials,
training materials, and community of developers and users. CNN Modeling Capability: Convolutional neural
networks (CNNs) are used for image recognition, recommendation engines,
and natural language processing. A CNN is composed of a set of distinct
layers that transform the initial data volume into output scores of
predefined class scores (For more information, check out Eugenio
Culurciello’s overview of Neural Network architectures).
CNN’s can also be used for regression analysis, such as models that
output of steering angles in autonomous vehicles. We consider a
technology’s CNN modeling capability to include several features. These
features include the opportunity space to define models, the
availability of prebuilt layers, and the tools and functions available
to connect these layers. We’ve seen that Theano, Caffe, and MXNet all
have great CNN modeling capabilities. That said, TensorFlow’s easy
ability to build upon it’s InceptionV3
model and Torch’s great CNN resources including easy-to-use temporal
convolution set these two technologies apart for CNN modeling
capability. RNN Modeling Capability: Recurrent neural networks
(RNNs) are used for speech recognition, time series prediction, image
captioning, and other tasks that require processing sequential
information. As prebuilt RNN models are not as numerous as CNNs, it is
therefore important if you have a RNN deep learning project that you
consider what RNN models have been previously implemented and open
sourced for a specific technology. For instance, Caffe has minimal RNN
resources, while Microsoft’s CNTK and Torch have ample RNN tutorials and prebuilt models. While vanilla TensorFlow has some RNN materials, TFLearn and Keras include many more RNN examples that utilize TensorFlow. Architecture: In order to create and train new
models in a particular framework, it is critical to have an easy to use
and modular front end. TensorFlow, Torch, and MXNet have a
straightforward, modular architecture that makes development
straightforward. In comparison, frameworks such as Caffe require
significant amount of work to create a new layer. We’ve found that
TensorFlow in particular is easy to debug and monitor during and after
training, as the TensorBoard web GUI application is included. Speed: Torch and Nervana have the best documented performance for open source convolutional neural network benchmarking tests. TensorFlow performance
was comparable for most tests, while Caffe and Theano lagged behind.
Microsoft’s CNTK claims to have some of the fastest RNN training time. Another study comparing Theano, Torch, and TensorFlow directly for RNN showed that Theano performs the best of the three. Multiple GPU Support: Most deep learning
applications require an outstanding number of floating point operations
(FLOPs). For example, Baidu’s DeepSpeech recognition models take 10s of ExaFLOPs to train. That is >10e18 calculations! As leading Graphics Processing Units (GPUs) such as NVIDIA’s Pascal TitanX can execute 11e9 FLOPs a second,
it would take over a week to train a new model on a sufficiently large
dataset. In order to decrease the time it takes to build a model,
multiple GPUs over multiple machines are needed. Luckily, most of the
technologies outlined above offer this support. In particular, MXNet is reported to have one the most optimized multi-GPU engine. Keras Compatible:Keras
is a high level library for doing fast deep learning prototyping. We’ve
found that it is a great tool for getting data scientists comfortable
with deep learning. Keras currently supports two back ends, TensorFlow
and Theano, and will be gaining official support in TensorFlow in the future. Keras is also a good choice for a high-level library when considering that its author recently expressed that Keras will continue to exist as a front end that can be used with multiple back ends.
If you are interested in getting started with deep learning, I would
recommend evaluating your own team’s skills and your project needs
first. For instance, for an image recognition application with a
Python-centric team we would recommend TensorFlow given its ample
documentation, decent performance, and great prototyping tools. For
scaling up an RNN to production with a Lua competent client team, we
would recommend Torch for its superior speed and RNN modeling
capabilities.
In the future we will discuss some of our challenges in scaling up
our models. These challenges include optimizing GPU usage over multiple
machines and adapting open source libraries like CMU Sphinx and Kaldi
for our deep learning pipeline.






 A procedure for performing such a model extraction attack was introduced
in the black-box attacks paper. The adversary can then use the
substitute model’s gradients to find adversarial examples that are
misclassified by the defended model as well. In the figure above,
reproduced from the discussion of gradient masking found in
A procedure for performing such a model extraction attack was introduced
in the black-box attacks paper. The adversary can then use the
substitute model’s gradients to find adversarial examples that are
misclassified by the defended model as well. In the figure above,
reproduced from the discussion of gradient masking found in