This is the second part of ‘A Brief History of Neural Nets and Deep Learning’. Part 1 is here, and Parts 3 and 4 are here and here. In this part, we will look into several strains of research that made rapid progress following the development of backpropagation and until the late 90s, which we shall see later are the essential foundations of Deep Learning.
Neural Nets Gain Vision

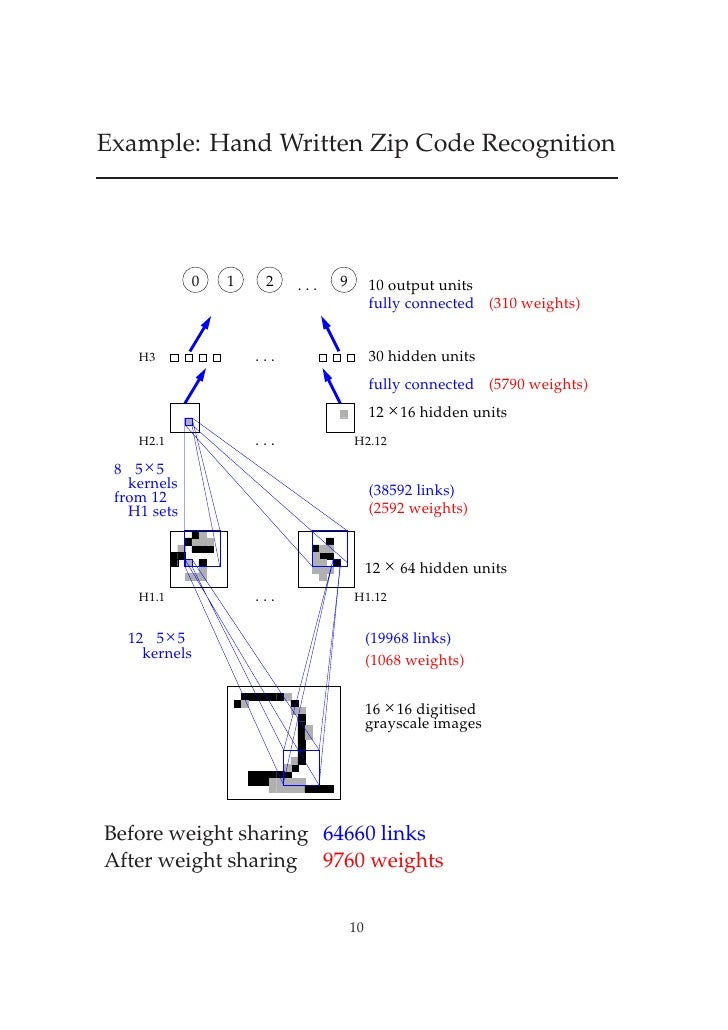
But, this is mathematics, where you could imagine having endless memory and computation power should it be needed - did backpropagation allow neural nets to be used for anything in the real world? Oh yes. Also in 1989, Yann LeCunn et al. at the AT&T Bell Labs demonstrated a very significant real-world application of backpropagation in "”Backpropagation Applied to Handwritten Zip Code Recognition”
“Classical work in visual pattern recognition has demonstrated the advantage of extracting local features and combining them to form higher order features. Such knowledge can be easily built into the network by forcing the hidden units to combine only local sources of information. Distinctive features of an object can appear at various location on the input image. Therefore it seems judicious to have a set of feature detectors that can detect a particular instance of a feature anywhere on the input place. Since the precise location of a feature is not relevant to the classification, we can afford to lose some position information in the process. Nevertheless, approximate position information must be preserved, to allow the next levels to detect higher order, more complex features (Fukushima 1980; Mozer 1987).”

{kind=link}

“According to the hierarchy model by Hubel and Wiesel, the neural network in the visual cortex has a hierarchy structure: LGB (lateral geniculate body)->simple cells->complex cells->lower order hypercomplex cells->higher order hypercomplex cells. It is also suggested that the neural network between lower order hypercomplex cells and higher order hypercomplex cells has a structure similar to the network between simple cells and complex cells. In this hierarchy, a cell in a higher stage generally has a tendency to respond selectively to a more complicated feature of the stimulus pattern, and, at the same time, has a larger receptive field, and is more insensitive to the shift in position of the stimulus pattern. … Hence, a structure similar to the hierarchy model is introduced in our model.”LeCun continued to be a major proponent of CNNs at Bell Labs, and his work on them resulted in major commercial use for check-reading in the mid 90s - his talks and interviews often include the fact that “At some point in the late 1990s, one of these systems was reading 10 to 20% of all the checks in the US.”
Neural Nets Go Unsupervised
Automating the rote and utterly uninteresting task of reading checks is a great instance of what Machine Learning can be used for. Perhaps a less predictable application? Compression. Meaning, of course, finding a smaller representation of some data from which the original data can be reconstructed. Learned compression may very well outperform stock compression schemes, in the case the learning algorithm can find features within the data stock methods would miss. And it is very easy to do - just train a neural net with a small hidden layer to just output the input:



Neural Nets Gain Beliefs
In fact, before being co-author of the seminal 1986 paper on backpropagation learning algorithm, Hinton worked on a neural-net approach for learning probability distributions in the 1985 “A Learning Algorithm for Boltzmann Machines”That there is a common theoretical framework for a bunch of learning methods is not too surprising, since at the end of the day all of learning boils down to optimization. Quoting from the above cited tutorial:
"Training an EBM consists in finding an energy function that produces the best Y for any X ... The architecture of the EBM is the internal structure of the parameterized energy function E(W, Y, X) ... This quality measure is called the loss functional (i.e. a function of function) and denoted L(E,S). ... In order to find the best energy function [] we need a way to assess the quality of any particular energy function, based solely on two elements: the training set, and our prior knowledge about the task. For simplicity, we often denote it L(W,S) and simply call it the loss function. The learning problem is simply to find the W that minimizes the loss."
So, the key to energy based models is recognizing all these algorithms are essentially different ways to optimize a pair of functions, that can be called the energy function E and loss function L, by finding a set of good values to a bunch of variables that can be denoted W using data denoted X for input and Y for the output. It's really a very broad definition for a framework, but still nicely encapsulates what a lot of algorithms fundamentally do.

{kind=link}

{kind=link}
“Perhaps the most interesting aspect of the Boltzmann Machine formulation is that it leads to a domain-independent learning algorithm that modifies the connection strengths between units in such a way that the whole network develops an internal model which captures the underlying structure of its environment. There has been a long history of failure in the search for such algorithms (Newell, 1982), and many people (particularly in Artificial Intelligence) now believe that no such algorithms exist.”
Without delving into the full details of the algorithm, here are some highlights: it is a variant on maximum-likelihood algorithms, which simply means that it seeks to maximize the probability of the net’s visible unit values matching with their known correct values. Computing the actual most likely value for each unit turns all at the same time out to be much too computationally expensive, so in training Gibbs Sampling - starting the net with random unit values and iteratively reassigning values to units given their connections’ values - is used to give some actual known values. When learning using a training set, the visible units are just set to have the value of the current training example, so sampling is done to get values for the hidden units. Once some ‘real’ values are sampled, we can do something similar to backpropagation - take a derivative for each weight to see how we can change so as to increase the probability of the net doing the right thing.Having learned the classical neural net models first, it took me a while to understand the notion behind these probabilistic nets. To elaborate, let me present a quote from the paper itself that restates all that I have said above quite well:
"The network modifies the strengths of its connections so as to construct an internal generative model that produces examples with the same probability distribution as the examples it is shown. Then, when shown any particular example, the network can “interpret” it by finding values of the variables in the internal model that would generate the example.
...
The machine is composed of primitive computing elements called units that are connected to each other by bidirectional links. A unit is always in one of two states, on or off, and it adopts these states as a probabilistic function of the states of its neighboring units and the weights on its links to them. The weights can take on real values of either sign. A unit being on or off is taken to mean that the system currently accepts or rejects some elemental hypothesis about the domain. The weight on a link represents a weak pairwise constraint between two hypotheses. A positive weight indicates that the two hypotheses tend to support one another; if one is currently accepted, accepting the other should be more likely. Conversely, a negative weight suggests, other things being equal, that the two hypotheses should not both be accepted. Link weights are symmetric, having the same strength in both directions (Hinton & Sejnowski, 1983)."
As with neural net, the algorithm can be done both in a supervised fashion (with known values for the hidden units) or in an unsupervised fashion. Though the algorithm was demonstrated to work (notably, with the same ‘encoding’ problem that autoencoder neural nets solve), it was soon apparent that it just did not work very well - Redford M. Neal’s 1992 “Connectionist learning of belief networks”

Finally, belief nets could be trained somewhat fast! Though not quite as influential, this algorithmic advance was a significant enough forward step for unsupervised training of belief nets that it could be seen as a companion to the now almost decade-old breakthrough that was backpropagation. But, by this point new machine learning methods had begun to also emerge, and people were again beginning to be skeptical of neural nets since so much of their ideas seemed intuition-based and since computers were still barely able to meet their computational needs. As we’ll see in part 3, a new AI Winter for neural nets began just a few years later…When Hinton talks of the Wake Sleep algorithm, he often notes how gross the simplifying assumption being made is, and that despite that the algorithm just works. Again I will quote as the paper itself explains the assumption well:
"The key simplifying assumption is that the recognition distribution for a particular example d, Q is factorial (separable) in each layer. If there are h stochastic binary units in a layer B, the portion of the distribution P(B,d) due to that layer is determined by 2^(h - 1) probabilities. However, Q makes the assumption that the actual activity of any one unit in layer P is independent of the activities of all the other units in that layer, given the activities of all the units in the lower layer, l - 1, so the recognition model needs only specify h probabilities rather than 2" - 1. The independence assumption allows F(d; 8.4) to be evaluated efficiently, but this computational tractability is bought at a price, since the true posterior is unlikely to be factorial
...
The generative model is taken to be factorial in the same way, although one should note that factorial generative models rarely have recognition distributions that are themselves exactly factorial."
Note the Neal's belief nets also implicitly made the probabilities factorize by having layers of units with only forward-facing directed connections.
-
Kurt Hornik, Maxwell Stinchcombe, Halbert White, Multilayer
feedforward networks are universal approximators, Neural Networks,
Volume 2, Issue 5, 1989, Pages 359-366, ISSN 0893-6080,
http://dx.doi.org/10.1016/0893-6080(89)90020-8. ↩
-
LeCun, Y; Boser, B; Denker, J; Henderson, D; Howard, R;
Hubbard, W; Jackel, L, “Backpropagation Applied to Handwritten Zip Code
Recognition,” in Neural Computation , vol.1, no.4, pp.541-551, Dec. 1989
89 ↩
-
D. E. Rumelhart, G. E. Hinton, and R. J. Williams. 1986.
Learning internal representations by error propagation. In Parallel
distributed processing: explorations in the microstructure of cognition,
vol. 1, David E. Rumelhart, James L. McClelland, and CORPORATE PDP
Research Group (Eds.). MIT Press, Cambridge, MA, USA 318-362 ↩ ↩2
-
Fukushima, K. (1980), ‘Neocognitron: A Self-Organizing Neural
Network Model for a Mechanism of Pattern Recognition Unaffected by Shift
in Position’, Biological Cybernetics 36 , 193–202 . ↩
-
Gregory Piatetsky, ‘KDnuggets Exclusive: Interview with Yann
LeCun, Deep Learning Expert, Director of Facebook AI Lab’ Feb 20, 2014.
http://www.kdnuggets.com/2014/02/exclusive-yann-lecun-deep-learning-facebook-ai-lab.html
↩
-
Teuvo Kohonen. 1988. Self-organized formation of topologically
correct feature maps. In Neurocomputing: foundations of research, James
A. Anderson and Edward Rosenfeld (Eds.). MIT Press, Cambridge, MA, USA
509-521. ↩
-
Gail A. Carpenter and Stephen Grossberg. 1988. The ART of
Adaptive Pattern Recognition by a Self-Organizing Neural Network.
Computer 21, 3 (March 1988), 77-88. ↩
-
H. Bourlard and Y. Kamp. 1988. Auto-association by multilayer
perceptrons and singular value decomposition. Biol. Cybern. 59, 4-5
(September 1988), 291-294. ↩
-
P. Baldi and K. Hornik. 1989. Neural networks and principal
component analysis: learning from examples without local minima. Neural
Netw. 2, 1 (January 1989), 53-58. ↩
-
Hinton, G. E. & Zemel, R. S. (1993), Autoencoders, Minimum
Description Length and Helmholtz Free Energy., in Jack D. Cowan; Gerald
Tesauro & Joshua Alspector, ed., ‘NIPS’ , Morgan Kaufmann, , pp.
3-10 . ↩
-
Ackley, D. H., Hinton, G. E., & Sejnowski, T. J. (1985). A
learning algorithm for boltzmann machines*. Cognitive science, 9(1),
147-169. ↩
-
LeCun, Y., Chopra, S., Hadsell, R., Ranzato, M., & Huang,
F. (2006). A tutorial on energy-based learning. Predicting structured
data, 1, 0. ↩
-
Neal, R. M. (1992). Connectionist learning of belief networks. Artificial intelligence, 56(1), 71-113. ↩
-
Hinton, G. E., Dayan, P., Frey, B. J., & Neal, R. M.
(1995). The” wake-sleep” algorithm for unsupervised neural networks.
Science, 268(5214), 1158-1161. ↩
-
Dayan, P., Hinton, G. E., Neal, R. M., & Zemel, R. S. (1995). The helmholtz machine. Neural computation, 7(5), 889-904. ↩
No comments:
Post a Comment